![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Research Projects | |
| Research at the Statistical Visual Computing Lab covers a wide range of subjects in the areas of computer vision, image processing, machine learning, and multimedia. Below are some descriptions of on-going or past projects. Please check the publications page too, as we currently do not have a web page for some of the projects. | |
 |
Learning Disentangled Representations for Controllable Synthesis Though generative models create high-quality-visuals, it lacks precise and intuitive control over the generated outputs, which is essential for achieving high-quality and purposeful creation. Our research tackles this challenge by leveraging disentangled representations, which transform complex data into independent, manipulable factors, and allows for granular creative control. Moving forward, our work has taken this further demonstrating the potential of Multimodal Large Language Models (MLLMs) can redefine the trajectory of generative AI, paving the way for more flexible and unified generative systems. |
 |
Probabilistic Deep Neural Networks for Trust-worthy Artificial Intelligence Deep learning models has become the backbone of modern computer vision systems, achieving striking success in a wide range of tasks from image to video understanding. While the benchmark performance of deep neural networks never appears to saturate as they are fed with more data and compute, real-world applications of these models often fall short of expectations. This is due to the presence of biases in the data, which misrepresents the underlying distribution and leads to poor generalization and discriminatory outcomes. We investigate the problem of bias in vision and multimodal learning systems, proposing methods to identify, measure, and mitigate biases in both the data and the models. |
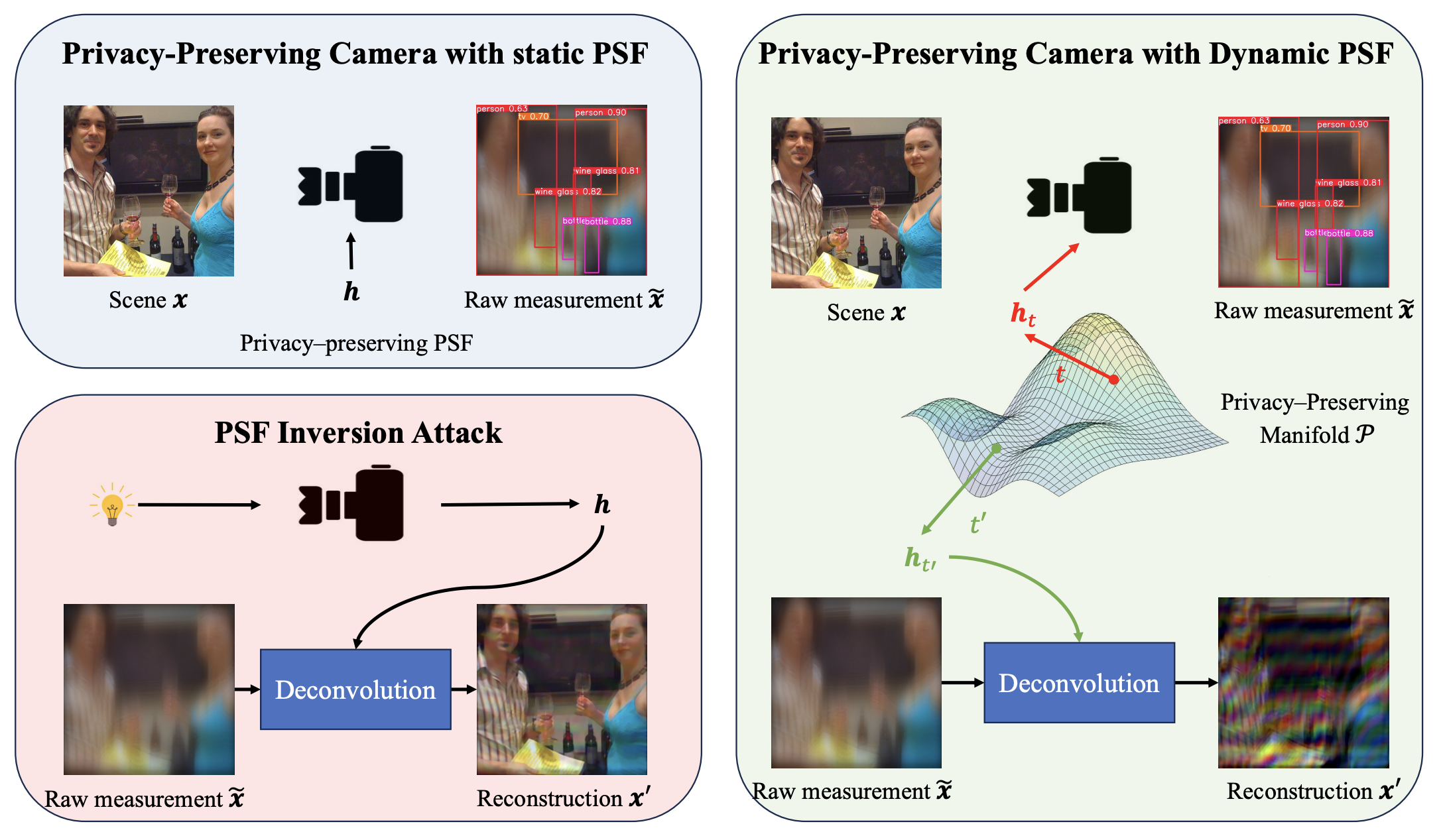 |
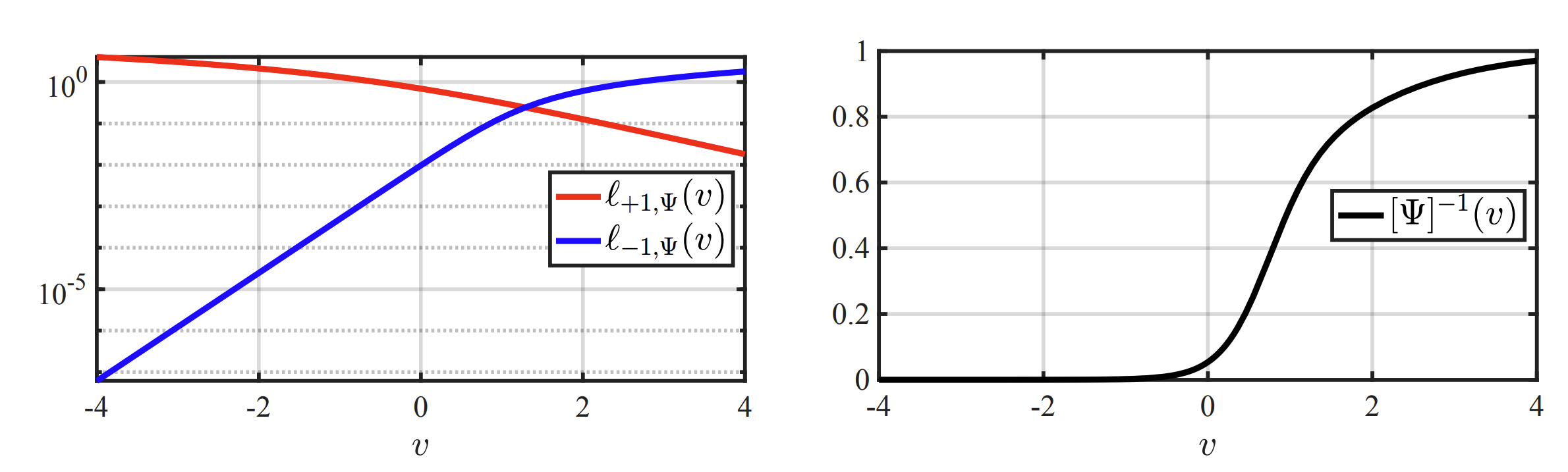
Learning a Dynamic Privacy-Preserving Camera Robust to Inversion Attacks This work addresses vulnerabilities in existing privacy-preserving cameras (PPCs) that use static point spread functions (PSFs), which can be compromised through PSF inversion attacks. We propose a dynamic privacy-preserving (DyPP) camera design that employs dynamic optical elements, such as spatial light modulators, to implement a time-varying PSF, changing with each captured image. These PSFs are randomly selected from a learned manifold embedding, trained adversarially to balance privacy (e.g., reducing face recognition accuracy) and task utility. |
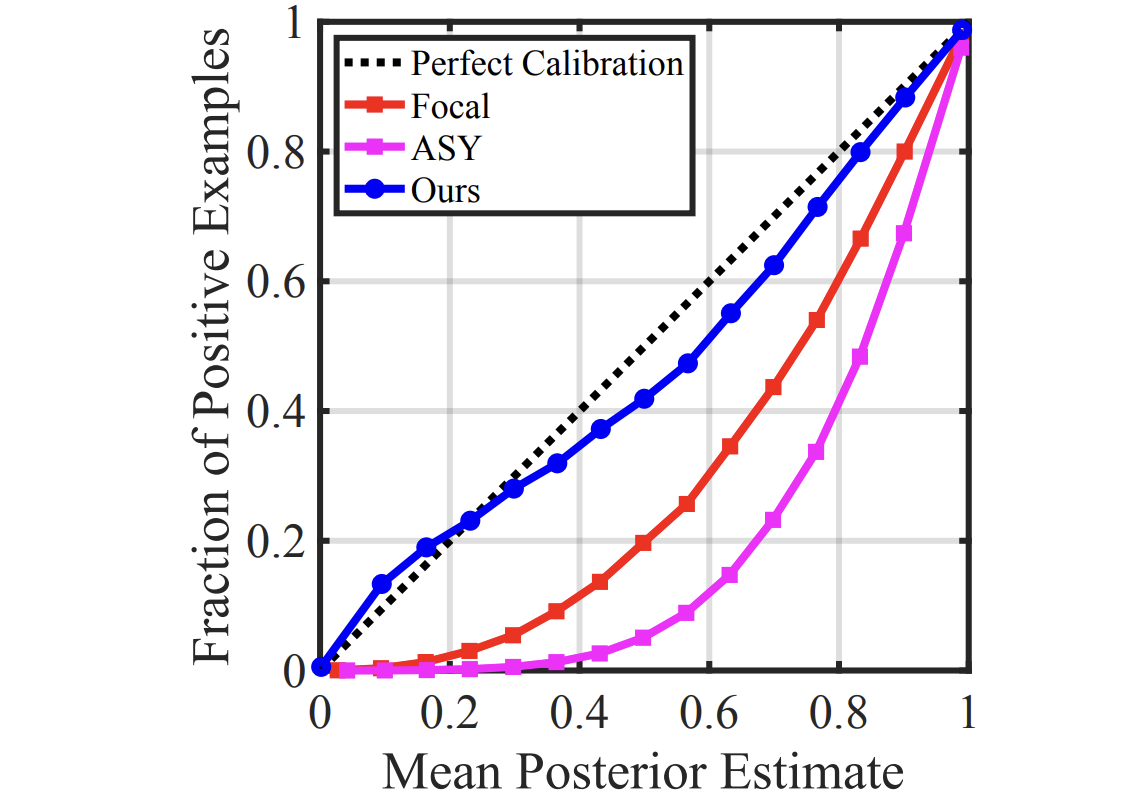 |
Towards Calibrated Multi-label Deep Neural Networks Deep neural networks (DNNs) used in multi-label learning often suffer from poor calibration. We identify that popular asymmetric losses, designed to handle class imbalance, lack the strictly proper property necessary for accurate probability estimation. To address this, the Strictly Proper Asymmetric (SPA) loss was proposed to enhance calibration constraints during training. Extensive experiments demonstrate that this approach significantly reduces calibration error while maintaining state-of-the-art accuracy. |
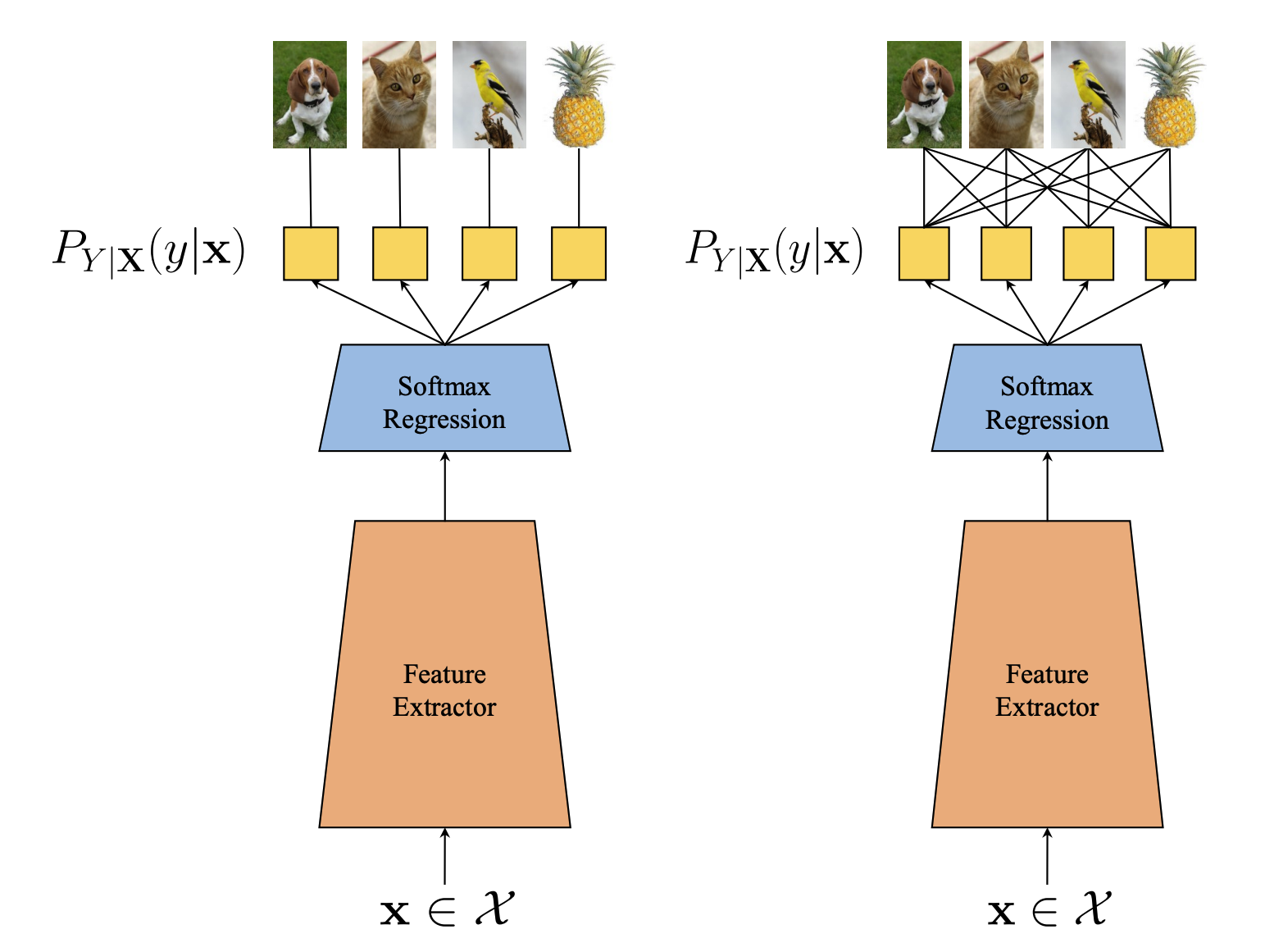 |
Calibrating Deep Neural Networks by Pairwise Constraints Deep neural networks (DNNs) often produce poorly calibrated class-posterior probabilities, primarily due to the cross-entropy loss focusing mainly on the true class probability and neglecting others. We propose that calibrating a C-class problem can be reframed as calibrating C(C-1)/2 pairwise binary classification tasks, suggesting that providing calibration supervision to all binary problems can enhance DNN calibration. We introduce the Calibration by Pairwise Constraints (CPC) method, which incorporates two types of binary calibration constraints with minimal additional complexity to standard training. |
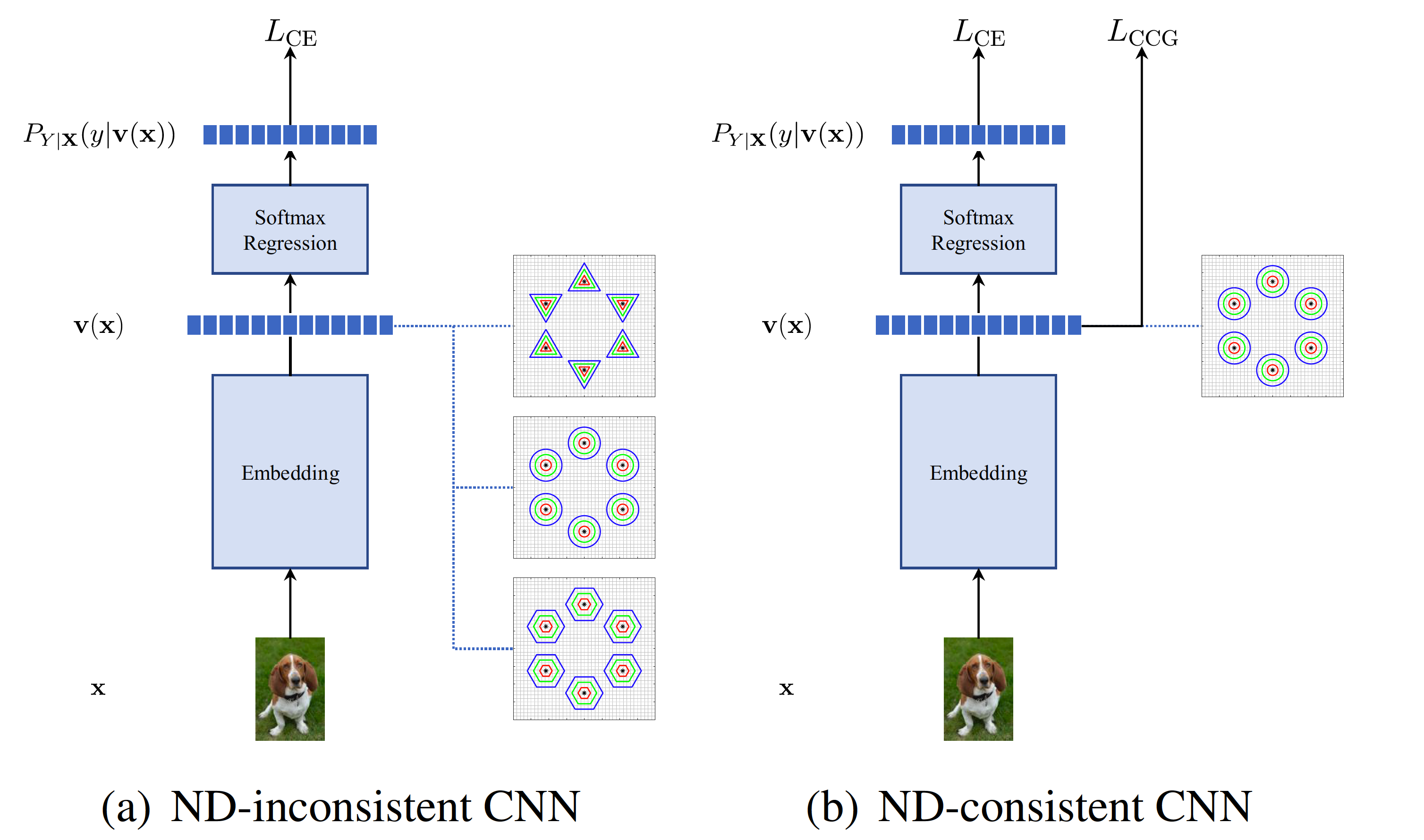 |
Learning Deep Classifiers Consistent with Fine-Grained Novelty Detection Fine-grained novelty detection remains a challenge in deep classification due to inconsistencies between classification objectives and novelty detection requirements. This paper proposes a novel Class-Conditional Gaussianity (CCG) loss, which regularizes deep classifiers to enforce Gaussian-like class-conditional distributions, improving both classification and novelty detection performance. By aligning feature space structures with theoretical optimality, the proposed method enhances outlier detection while maintaining high classification accuracy. Extensive experiments demonstrate that this approach outperforms existing methods in fine-grained visual classification tasks. |
 |
Holistic Bias Mitigation in Computer Vision and Beyond Deep learning models has become the backbone of modern computer vision systems, achieving striking success in a wide range of tasks from image to video understanding. While the benchmark performance of deep neural networks never appears to saturate as they are fed with more data and compute, real-world applications of these models often fall short of expectations. This is due to the presence of biases in the data, which misrepresents the underlying distribution and leads to poor generalization and discriminatory outcomes. We investigate the problem of bias in vision and multimodal learning systems, proposing methods to identify, measure, and mitigate biases in both the data and the models. |
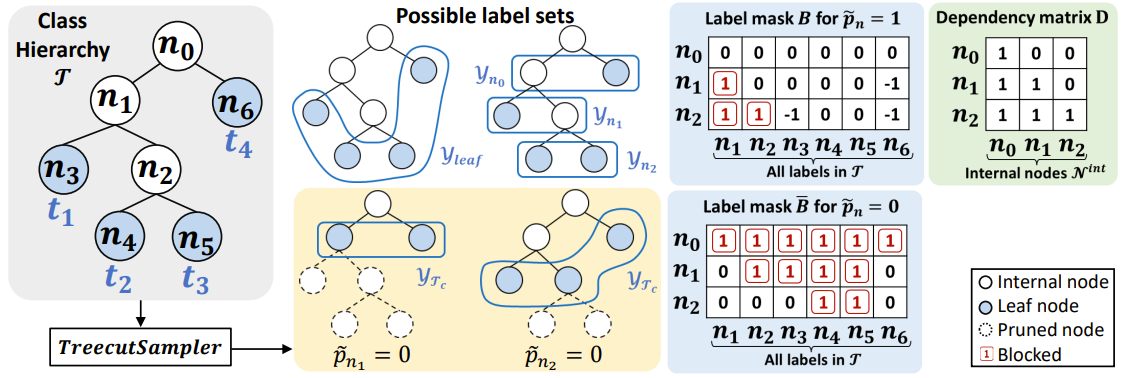 |
ProTeCt: Prompt Tuning for Taxonomic Open Set Classification Visual-language foundation models learn generalized representations that enable zero-shot open-set classification. However, these methods underperforms in the taxonomic open set (TOS) setting, where the classifier is asked to make prediction from label set across different levels of semantic granularity. We propose a new Prompt Tuning for Hierarchical Consistency (ProTeCt) technique to calibrate classification across label set granularities. Results show that ProTeCt significantly improve TOS classification. |
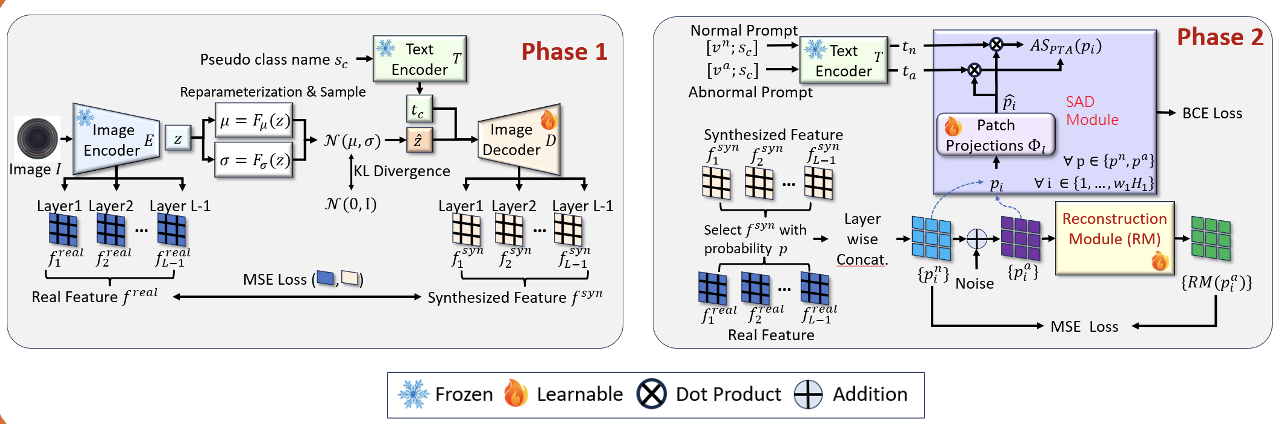 |
Long-Tailed Anomaly Detection with Learnable Class Names Anomaly detection (AD) identify defective images and localize their defects. Ideally, AD models should be able to detect defects over many image classes; without relying on hard-coded uninformative class names; and be robust to the long-tailed distributions of real-world applications. We propose a novel method, LTAD, to detect defects from multiple and long-tailed classes, without relying on dataset class names. Experiments show that LTAD outperforms prior methods on most of the proposed long-tailed datasets. |
 |
Toward Unsupervised Realistic Visual Question Aanswering The problem of realistic VQA (RVQA), where a model has to reject unanswerable questions (UQs) and answer answerable ones (AQs), is studied. We propose a new testing dataset, RGQA with around 29K human-annotated UQs. These UQs consist of both fine-grained and coarse-grained image-question pairs generated with 2 ways: CLIP-based and Perturbation-based. We then introduce an unsupervised training approach with pseudo UQs, RoI Mixup and model ensembling. Experiments show that the proposed method outperforms prior RVQA baselines. |
 |
Understanding Learned Visual Invariances Through Hierarchical Dataset Design and Collection Robust generalization across domain, viewpoint, and class remains a significant challenge in vision. This project centers around a hierarchical multiview, multidomain image dataset with 3D meshes called 3D-ODDS. Data was collected involving turntable setups, flying drones, and in-the-wild photos under diverse indoor/outdoor locations. For single view 3D reconstruction, a novel postprocessing step involving test-time self-supervised learning is proposed. For image classification, we consider an adversarial attack framework using perturbations which are semantically imperceptible. For both tasks, experiments show that 3D-ODDS is useful in measuring class, pose, and domain invariance. |
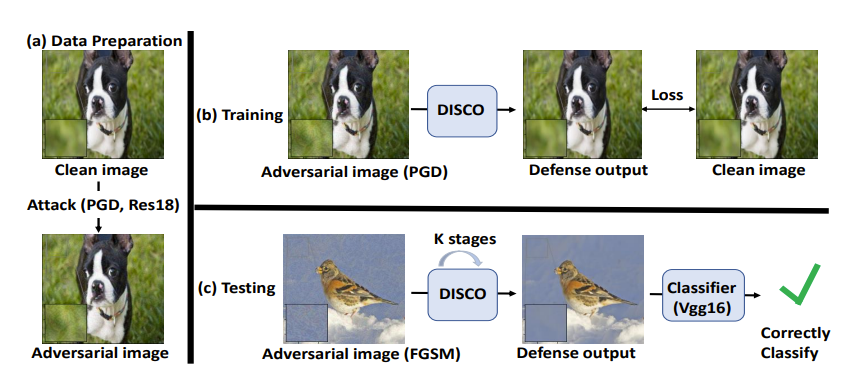 |
DISCO: Adversarial Defense with Local Implicit Functions The problem of adversarial defenses for image classification is considered. Inspired by the hypothesis that these examples lie beyond the natural image manifold, a novel aDversarIal defenSe with local impliCit functiOns (DISCO) is proposed. DISCO consumes an adversarial image and a query pixel location and outputs a clean RGB value at the location. It is implemented with an encoder and a local implicit module, where the former produces per-pixel deep features and the latter uses the features in the neighborhood of query pixel for predicting the clean RGB value. DISCO is shown to be data and parameter efficient and to mount defenses that transfers across datasets, classifiers and attacks. |
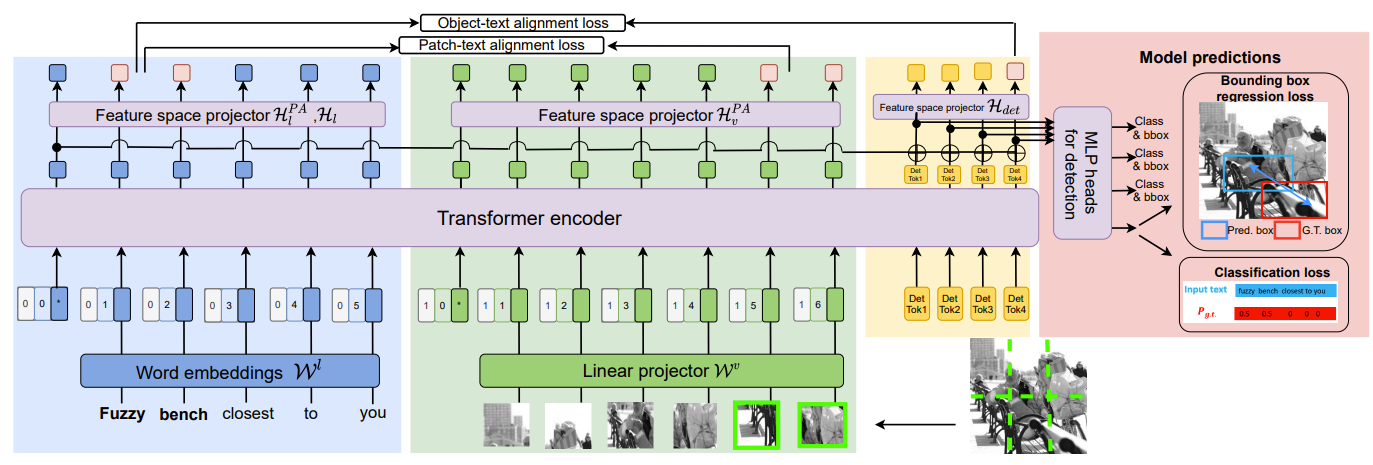 |
YORO - Lightweight End to End Visual Grounding We present YORO - a multi-modal transformer encoder-only architecture for the Visual Grounding (VG) task. YORO seeks a better trade-off between speed an accuracy by embracing a single-stage design, without CNN backbone. YORO consumes natural language queries, image patches, and learnable detection tokens and predicts coordinates of the referred object, using a single transformer encoder. To assist the alignment between text and visual objects, a novel patch-text alignment loss is proposed. Extensive experiments are conducted on 5 different datasets with ablations on architecture design choices. YORO is shown to support real-time inference and outperform all approaches in this class (single-stage methods) by large margins. |
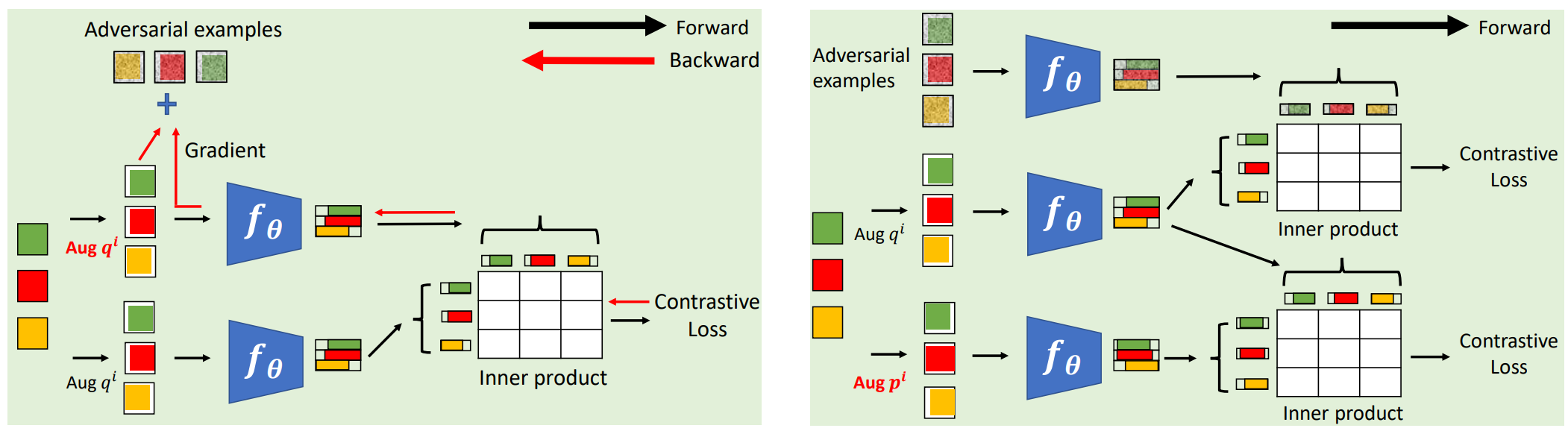 |
Contrastive Learning with Adversarial Examples This paper addresses the problem that prior contrastive learning (CL) works do not address the selection of challenging negative pairs. We introduce a new family of adversarial examples for constrastive learning and using these examples to define a new adversarial training algorithm for SSL, denoted as CLAE. When compared to standard CL, the use of adversarial examples creates more challenging positive pairs and adversarial training produces harder negative pairs by accounting for all images in a batch during the optimization. CLAE is compatible with many CL methods in the literature. Experiments show that it improves the performance of several existing CL baselines on multiple datasets. |
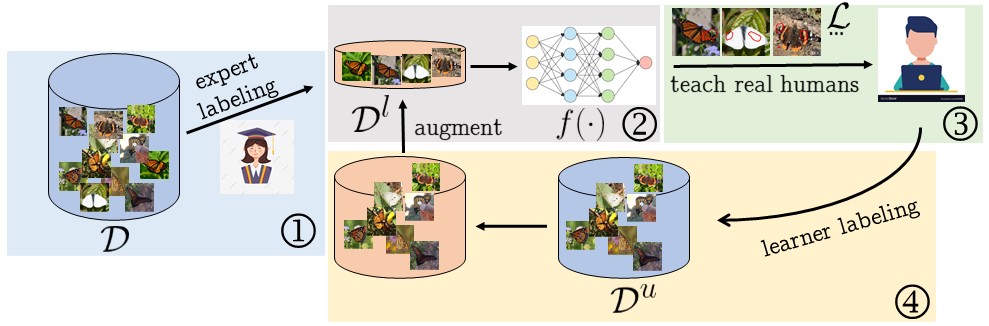 |
Explainable AI and its application to machine teaching Unlike other literature that tries to interpret the behavior of neural networks by Explainable AI, we instead in this project aim to take advantage of the powerfulness of XAI results for machine teaching problems where its goal is to design systems that can teach real students new concepts efficiently and automatically. We propose two visualization methods, deliberative explanations and counterfactual explanations and show their benefits on machine teaching and fine grained scalable recognition. |
 |
Rethinking and Improving the Robustness of Image Style Transfer We study the lack of robustness of stylization algorithms for non-VGG architectures. This showed that a significant factor is the use of residual connections, which decreases the entropy of deeper layer activations. A simple solution was proposed by adding activation smoothing to the loss functions used for stylization, using a softmax function. This was denoted as SWAG, and shown to be effective for various architectures, forms of pre-training (random vs. ImageNet), and stylization algorithms. It was shown that, with the addition of SWAG, the lightweight non-VGG becomes a viable alternative to VGG in future stylization work. |
 |
Image Synthesis by Image-Guided Model Inversion We propose the IMAGINE for image synthesis from one single training image. Instead of training a GAN model, IMAGINE synthesizes images by matching various levels of semantic features of a pre-trained classifier. |
 |
Dynamic Networks for Resource Constrained Image Recognition Two types of resource restrictions, i.e. computational resource constrain and limitation of annotated data, form a big obstacle for further improvement of computation vision tasks. A paradigm shift from static models with input invariant parameters to dynamic models with input dependant parameters is proposed for both kinds of issues. The strong power of the dynamic model shows a perfect choice for such resource restriction problems. |
 |
Learning of Visual Relations: The Devil is in the Tails Recent efforts in visual relation modeling have primarily focused on designing complex architectures. However, due to the combinatorial nature of joint reasoning about entities and predicates, visual relation learning is inherently a long-tailed problem. Complex models tend to overfit in such scenarios. In this study, we propose an alternative approach, termed the Devil is in the Tails hypothesis, suggesting that better performance can be achieved by simplifying models while enhancing their capability to handle long-tailed distributions. Results show that DT2-ACBS achieves significant performance improvements on scene graph generation tasks with a remarkably compact architecture, surpassing more complex state-of-the-art methods. |
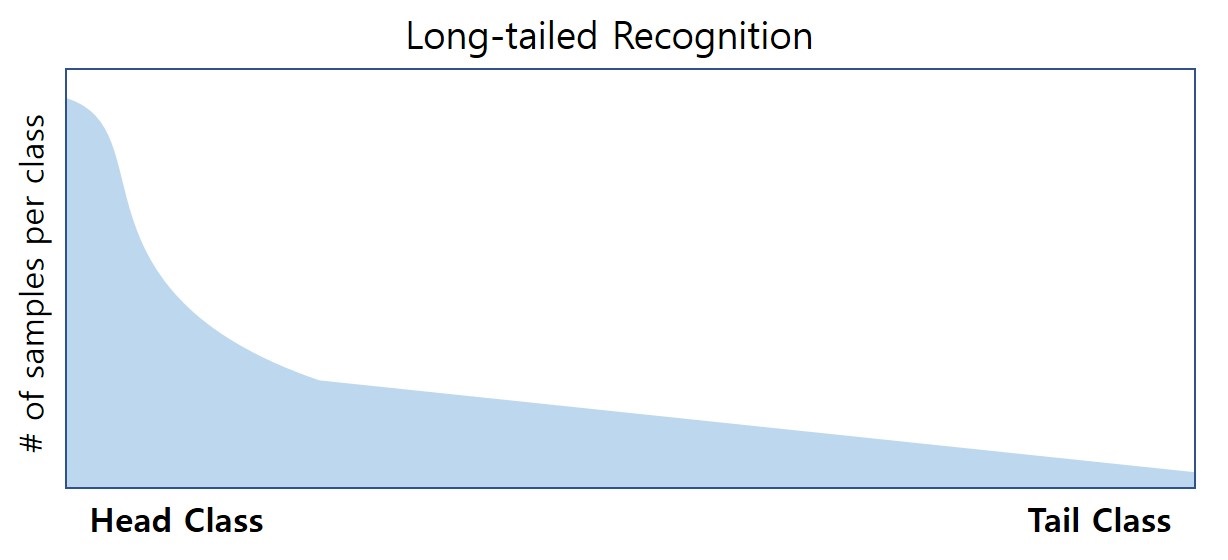 |
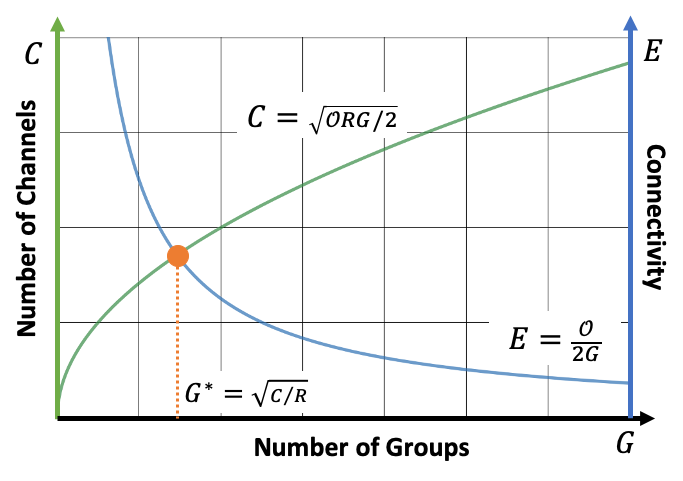
To Overcome the Long-tailed Problem in Computer Vision Real world images are not formulated as balanced ideal datasets. In fact, some objects are much easier to find than others. This yields a long-tailed distribution of the samples from different categories. To overcome this, people have discussed different sampling strategies to train different part of the recognition model. In this project, we introduce three works. The first work enhances the few-shot performance by introducing semi-supervised learning on unlabeled data. The second, extends class-balanced sampling to adversarial feature augmentation. And the last combines the two training stages with geometric structure transfer. |
 |
MicroNet: Towards Image Recognition with Extremely Low FLOPs We found the model's performance will be substantially decreased when its computational cost is extremely low (e.g. 5M FLOPs on ImageNet classification) due to two reasons, i.e, the width and depth reduction to save FLOPs. Based on the findings, two design principles, i.e. sparse connectivity and dynamic activation function, are proposed to effectively improve the accuracy without inducing too much extra computation. The former avoids the significant reduction of network width, while the latter mitigates the detriment of reduction in network depth. |
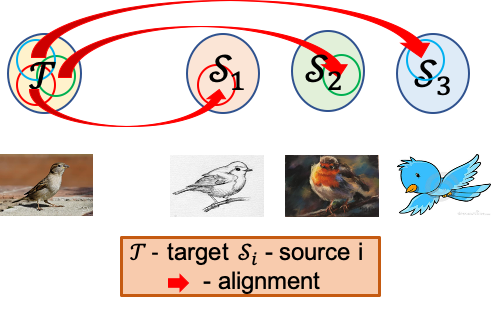 |
Dynamic Transfer for Multi-Source Domain Adaptation While working on multi-source domain adaptation problem, a static model difficult to handle conflicts across multiple domains, and suffers from a performance degradation in both source domains and target domain. To overcome the domain conflict, we propose dynamic transfer where the model parameters are adapted to samples. The key insight is that adapting model across domains is achieved via adapting model across samples. Thus, it breaks down source domain barriers and turns multi-source domains into a single-source domain, both of which improve the adaptation performance as well as simplify the problem. |
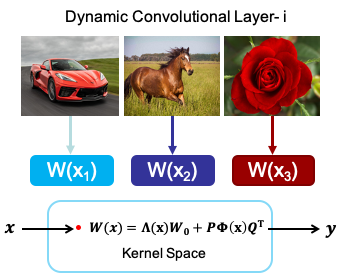 |
Revisiting Dynamic Convolution via Matrix Decomposition Dynamic convolution, which is an effective method to improve the neural network's representation ability, is revisited based on its two limitations, i.e. the model redundancy and hardness of optimization. From the perspective of matrix decomposition, we reveal the key issue is that dynamic convolution applies dynamic attention over channel groups after projecting into a higher dimensional latent space. To address this issue, a dynamic channel fusion technique named dynamic convolution decomposition is presented and achievs a good performance. |
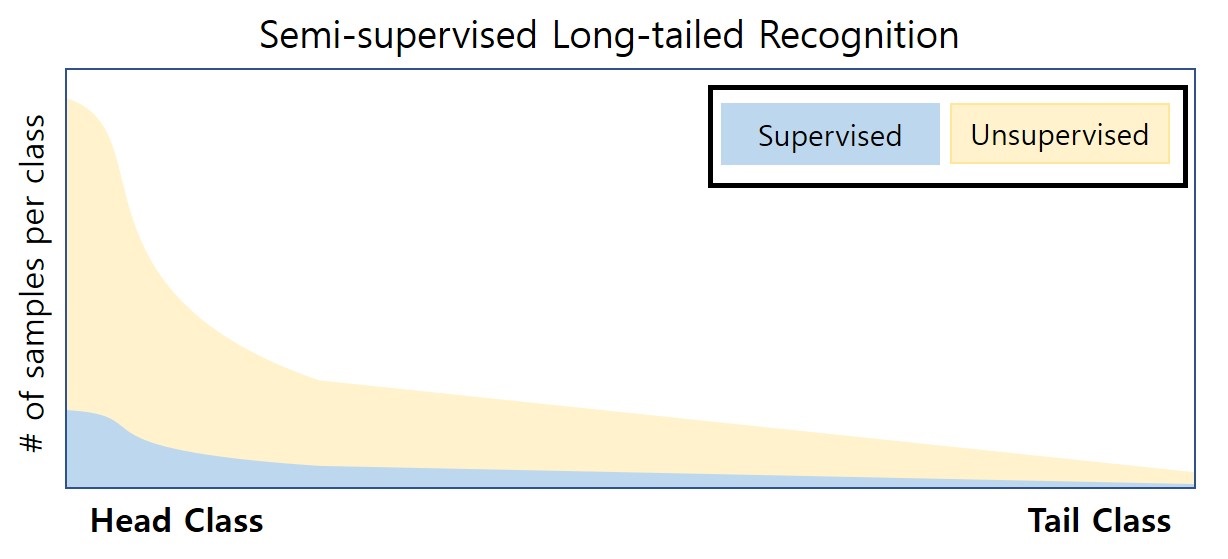 |
Semi-supervised Long-tailed Recognition using Alternate Sampling Main challenges in long-tailed recognition come from the imbalanced data distribution and sample scarcity in its tail classes. We resort to leverage readily available unlabeled data to boost recognition accuracy. The idea leads to a new recognition setting, namely semi-supervised long-tailed recognition. To address the semi-supervised long-tailed recognition problem, we present an alternate sampling framework combining the intuitions from successful methods in these two research areas. |
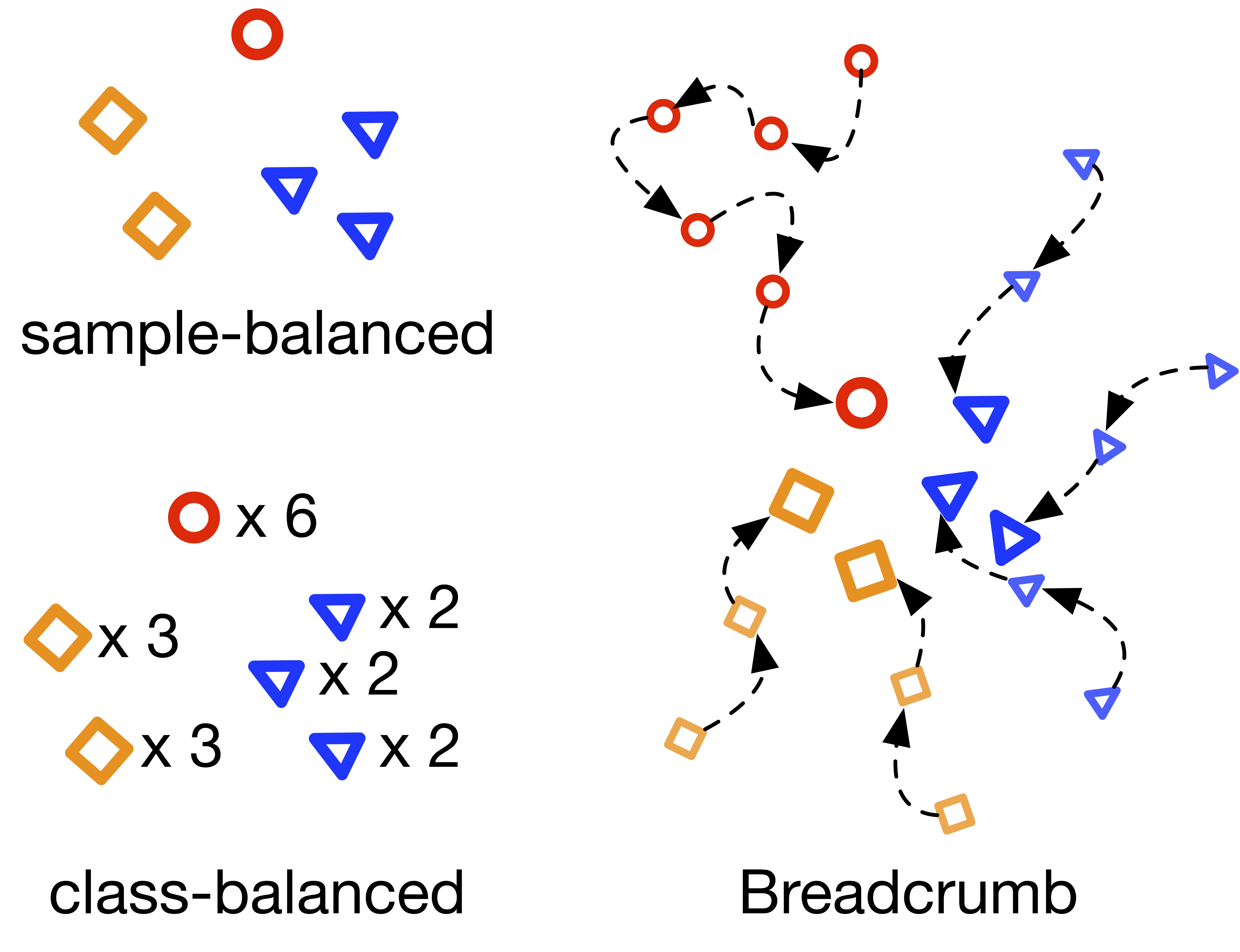 |
Breadcrumbs: Adversarial Class-balanced Sampling for Long-tailed Recognition Breadcrumbs is an adversarial class-balanced sampling method that replaces the regular class-balanced sampling during the training of classifier. It augments feature space by feature back-tracking. By dong this, Breadcrumbs avoids the sample level over-fitting on few-shot classes. |
 |
GistNet: a Geometric Structure Transfer Network for Long-tailed Recognition The problem of long-tailed recognition, where the number of examples per class is highly unbalanced, is considered. It is hypothesized that the well known tendency of standard classifier training to overfit to popular classes can be exploited for effective transfer learning. Rather than eliminating this overfitting, e.g. by adopting popular class-balanced sampling methods, the learning algorithm should instead leverage this overfitting to transfer geometric information from popular to low-shot classes. A new classifier architecture, GistNet, is proposed to support this goal, using constellations of classifier parameters to encode the class geometry. |
 |
Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier Long-tail recognition addresses the challenge of uneven performance accross class popularities, where tail class performance declines sharply. Humans, however, offer braoder predictions for uncertain examaplese. Inspired by this, we introduce Deep-RTC, a deep realistic taxonomic classifier designed to tackle the long-tail problem. It combines realism with hierarchical predictions and includes a mechanism to reject classification at different taxonomy levels when performance cannot be guaranteed. Results show that Deep-RTC can improve performance accross class popularities and is suitable for long-tail recognition. |
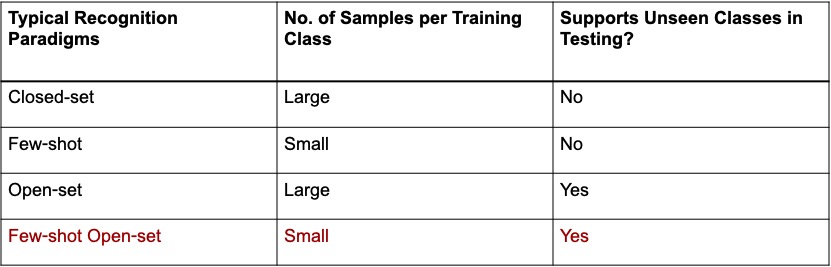 |
Few-shot Open-set Recognition using Meta-learning It is argued that the classic softmax classifier is a poor solution for open-set recognition, since it tends to overfit on the training classes. Randomization is then proposed as a solution to this problem. This suggests the use of meta-learning techniques, commonly used for few-shot classification, for the solution of open-set recognition. A new oPen sEt mEta LEaRning (PEELER) algorithm is then introduced. This combines the random selection of a set of novel classes per episode, a loss that maximizes the posterior entropy for examples of those classes, and a new metric learning formulation based on the Mahalanobis distance. |
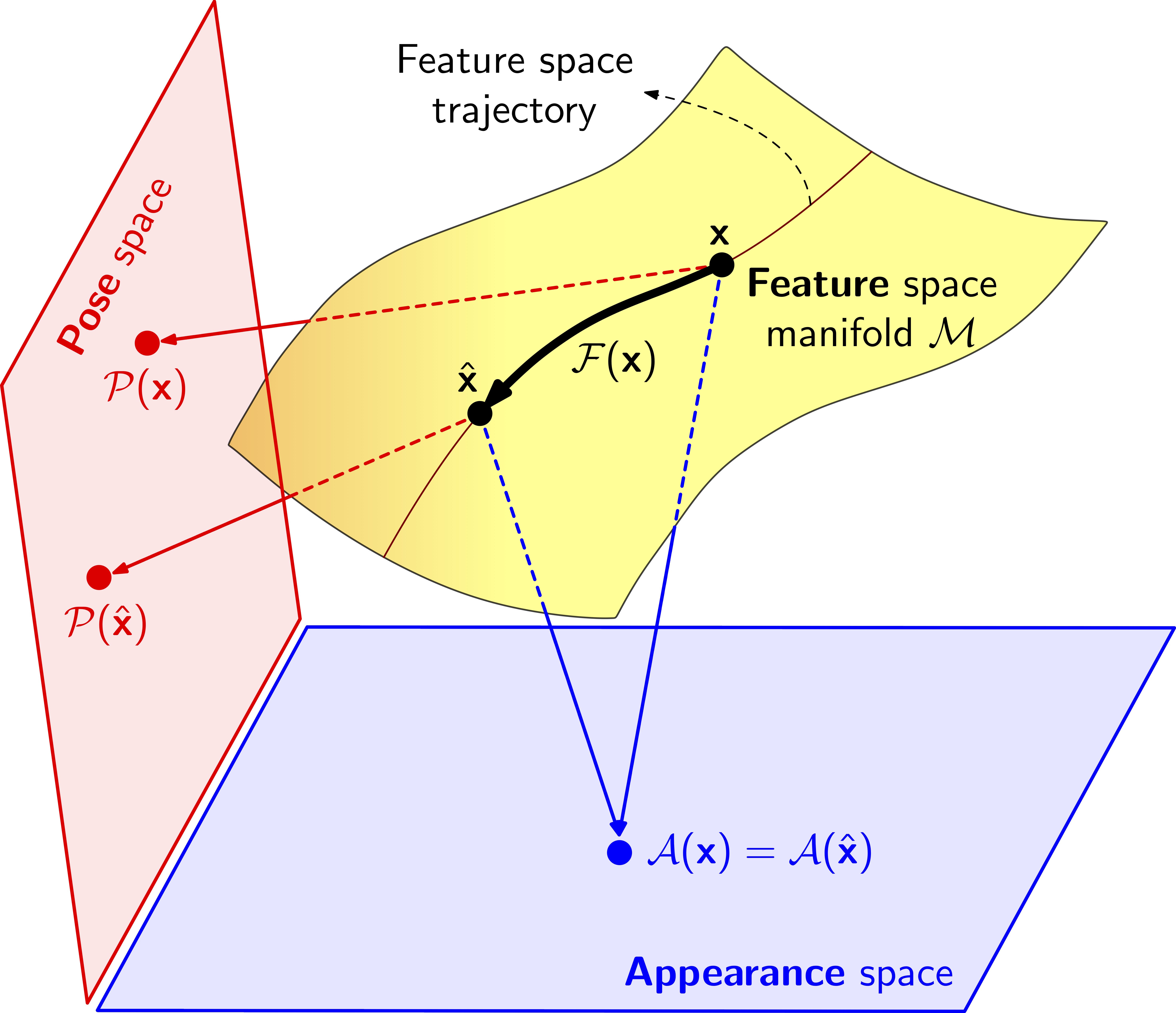 |
Feature Space Transfer as Data Augmentation for Few-shot Classification and Single-view Reconstruction The problem of data augmentation in feature space is considered. A new architecture, denoted the FeATure TransfEr Network (FATTEN), is proposed for the modeling of feature trajectories induced by variations of object pose. This architecture exploits a parametrization of the pose manifold in terms of pose and appearance. It is then applied for few-shot recognition and single-view reconstruction. |
 |
Bayesian Model Adaptation for Crowd Counts The problem of transfer learning is considered in the domain of crowd counting. A solution based on Bayesian model adaptation of Gaussian processes is proposed. A large video dataset for the evaluation of adaptation approaches to crowd counting is also introduced. This contains a number of adaptation tasks, involving information transfer across videos. |
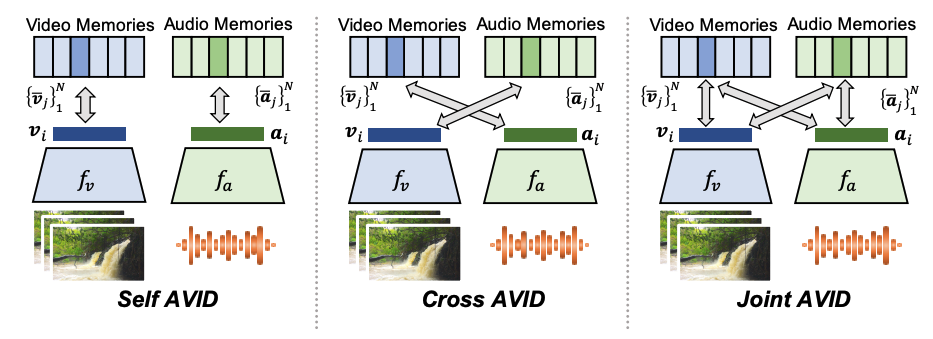 |
Audio-visual self-supervised learning Naturally co-occurring signals like audio and video can be used to learn powerful representations without relying on costly human annotations. We introduce an effective contrastive learning framework that learns strong video representations from audio supervision, identify and propose solutions for critical challenges inherent to this type of supervision, and show the benefits of audio-visual learning for tasks such as representation learning for action and audio recognition, visually-driven sound source localization, and spatial sound generation. |
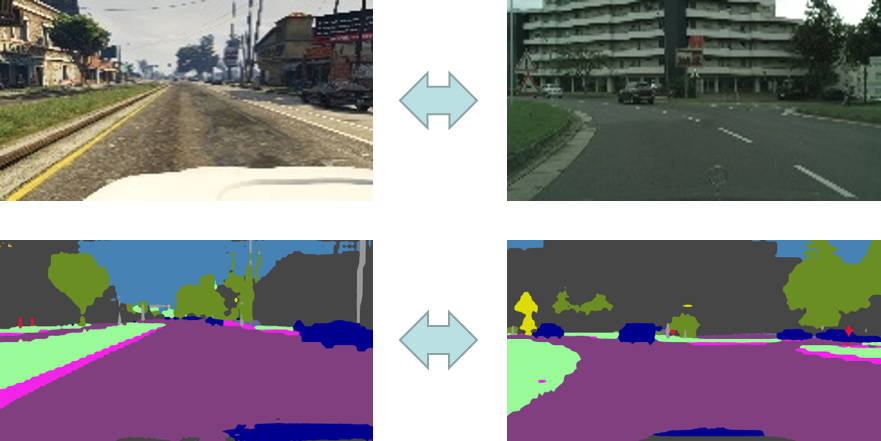 |
Bidirectional Learning for Domain Adaptation of Semantic Segmentation Domain adaptation for semantic segmentation is developped for saving annotation efforts via leveraging the automatically labeled synthetic data. A bidirectional learning method is presented to reduce the domain gap between synthetic images and real images. Within the framework of bidirectional learning, the image translation model and the segmentation adaptation model can be learned alternatively and promote to each other. |
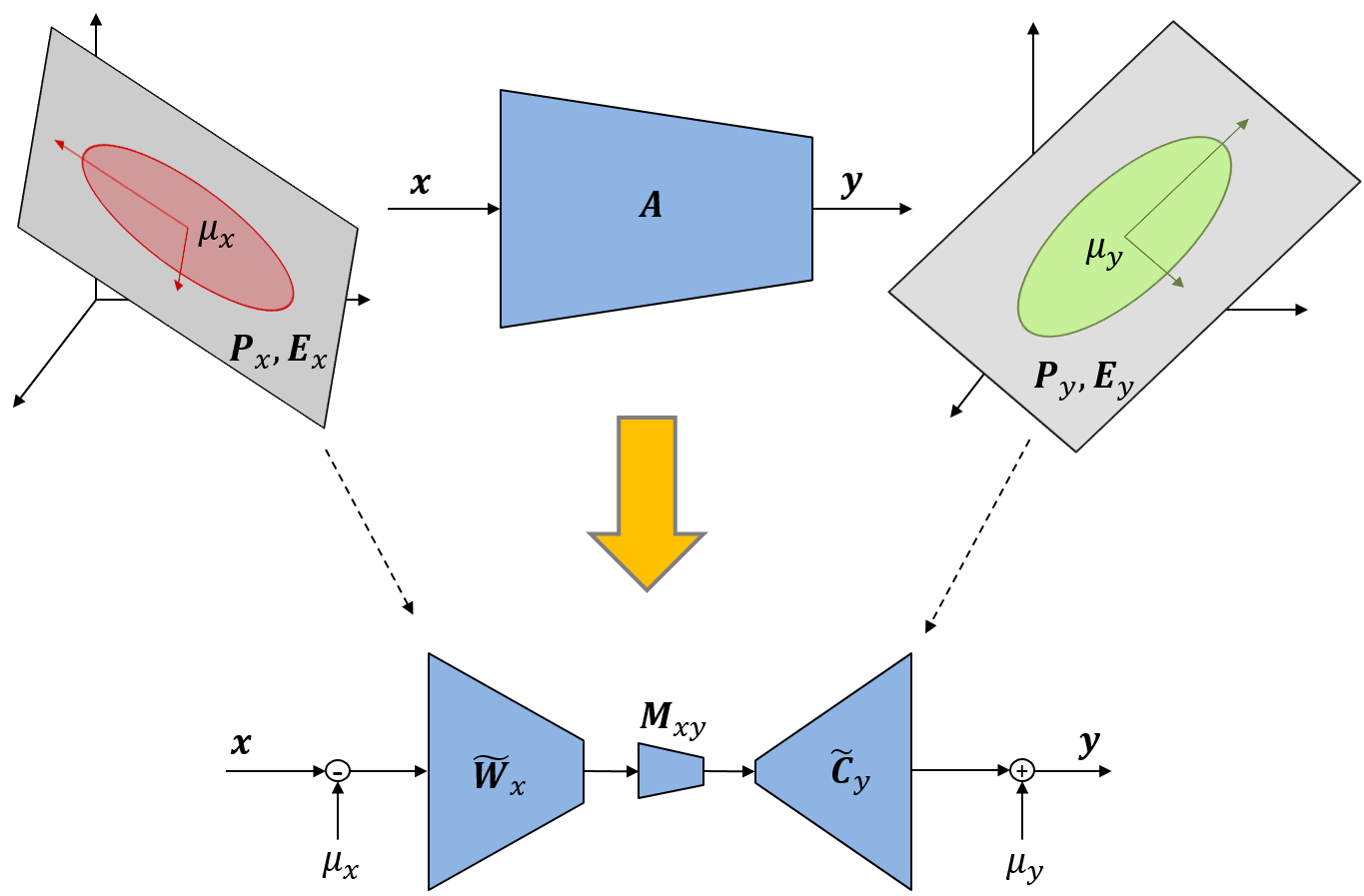 |
Efficient Multi-Domain Learning by Covariance Normalization Multi-domain learning aims to learn a generic model to work on multiple tasks. To fully reuse the model for different tasks, covariance normalization (CovNorm) is proposed with an adaptive layer per target domain and other layers shared across tasks. Due to the small size of the adaptive layer, the extra cost per target domain is limited, which achieves the goal of applying a tiny amount of computation on a large scales of tasks. |
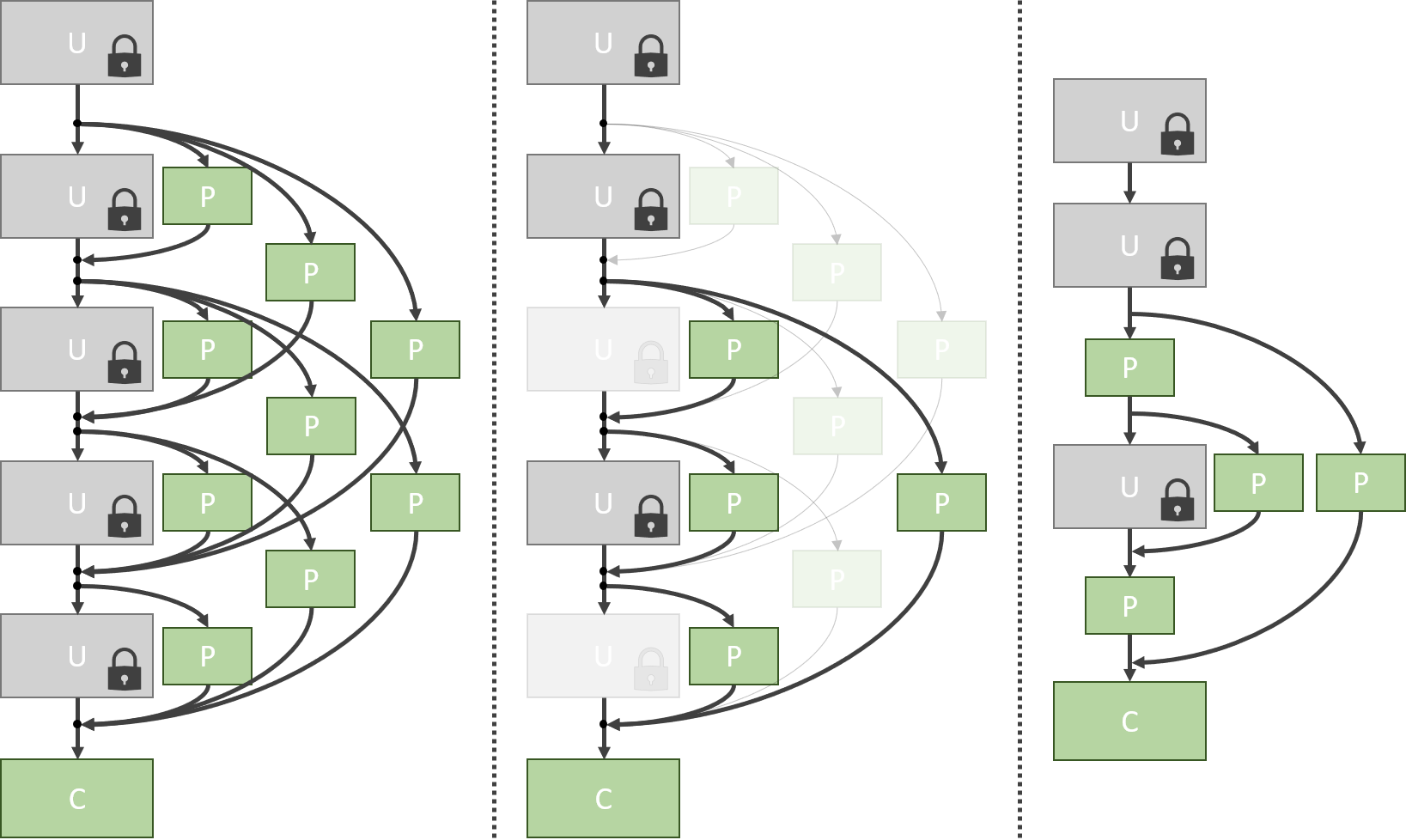 |
Architecture tuning for multi-domain recognition Real-world applications of object recognition often require efficiently solving multiple tasks in a single platform. To address this problem, we propose a transfer learning procedure in which layers of a pre-trained CNN are used as universal blocks that can be combined with small task-specific layers to generate new architectures for each task. |
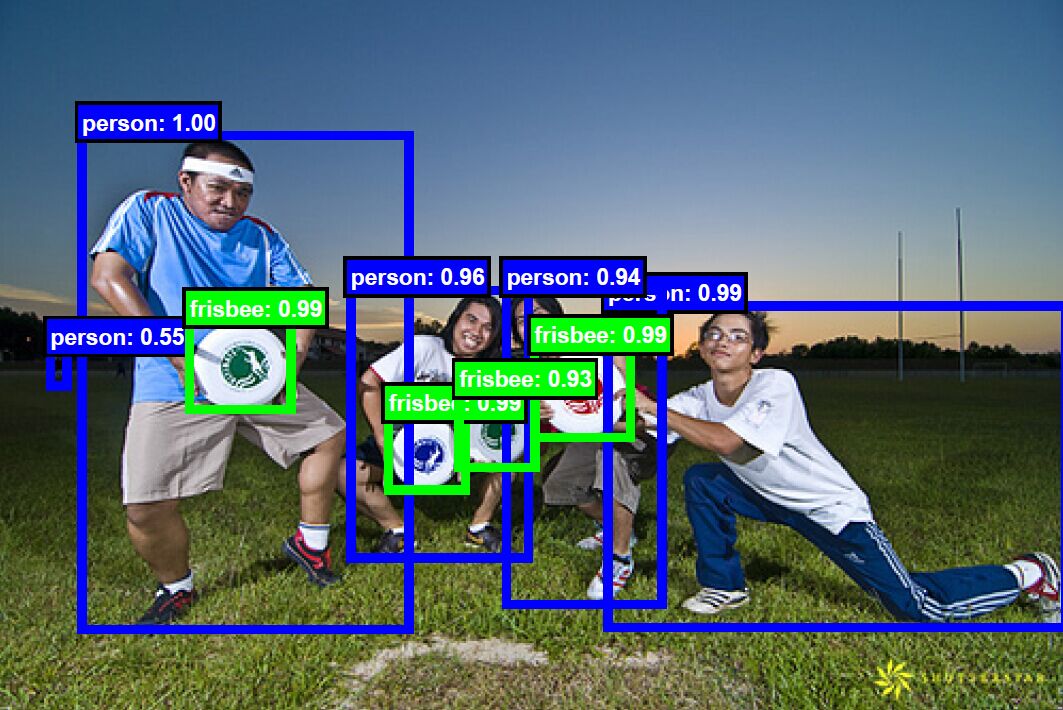 |
High-Quality Object Detection Cascade R-CNN is a novel and very simple architecture for high-quality object detection. The detection results have tight coverage with the ground-truth objects. The Cascade R-CNN has achieved the state-of-the-art performance on many popular object detection datasets, including COCO, and it is widely used by the winning teams in many object detection challenges. |
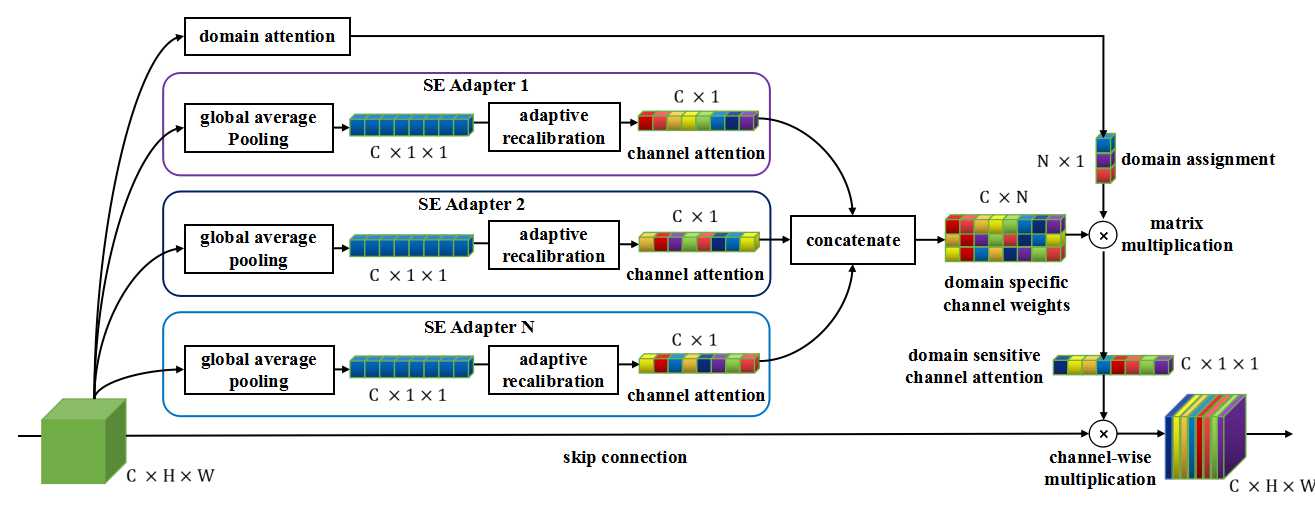 |
Universal Object Detection We introduced a new universal object detector, which can work for a large number of different domains, from everyday objects and face to medical lesion. The computations and parameters are shared across domains. It can outperform the domain-specific object detector sometimes. |
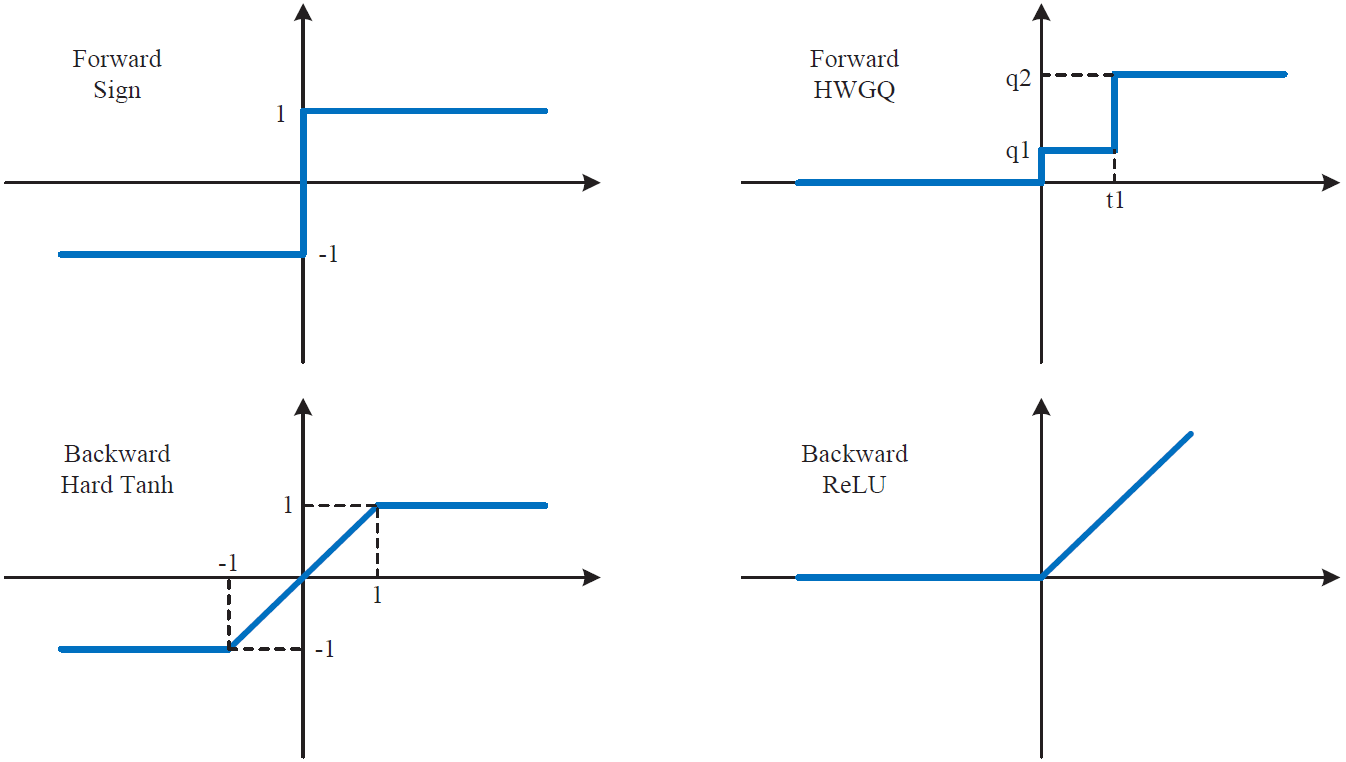 |
Low-precision Neural Networks HWGQ is a new quantization technique for low-precision neural networks, in which both weights and activations are quantized to low bit-width. This will substantially reduce the model size and computation by about 32 times, enabling neural networks to run on non-GPU devices, e.g. CPU or FPGA. The HWGQ-Net also achieved very close performance to full-precision baselines for almost all popular networks, including AlexNet, VGG-Net, ResNet, GoogleNet. |
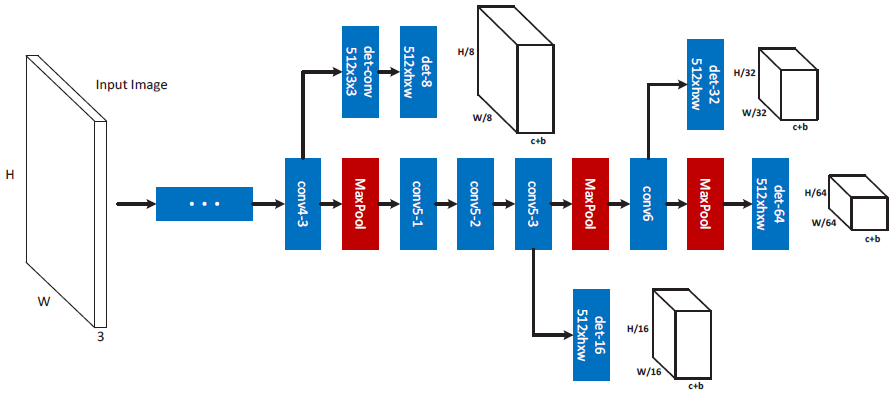 |
Multi-Scale Object Detection MS-CNN is an effcient and effective multi-scale object detection architecture, which has achieve state-of-the-art results on multiple detection tasks, including vehicle, pedestrian, face, etc., at real-time running speeds. |
 |
Objects Obtained With fLight (OOWL) The OOWL dataset is a real-world multiview dataset collected with drones, enabling flexibility and scalability. Currently OOWL contains 120,000 images of 500 objects and is the largest "in the lab" multiview image dataset available when both number of classes and objects per class are considered. OOWL is designed to have large class overlap with ImageNet and ModelNet, and has multiple domains. |
 |
Self-Supervised Generation of Spatial Audio for 360° Video We introduce an approach to convert mono audio recorded by a 360° video camera into spatial audio, a representation of the distribution of sound over the full viewing sphere. Our system consists of end-to-end trainable neural networks that separate individual sound sources and localize them on the viewing sphere, conditioned on multi-modal analysis of audio and 360° video frames. We introduce several datasets consisting of 360° videos with spatial audio. |
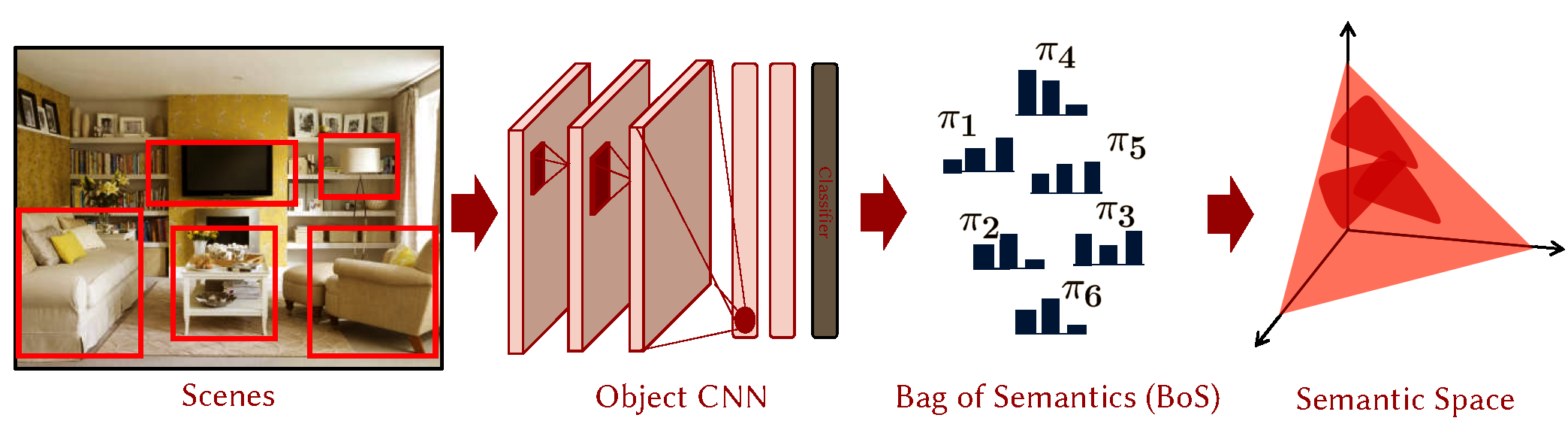 |
CNN based Semantic Transfer We investigate the feasibility of Across domain transfer in vision, specifically in the case where source domain is that of objects and target domain is holistic scenes. We approach the problem using a the description of a scene as a Bag-of-Semantics (BoS). Sophisticated non-linear embeddings of a scene BoS are proposed for holistic inference. |
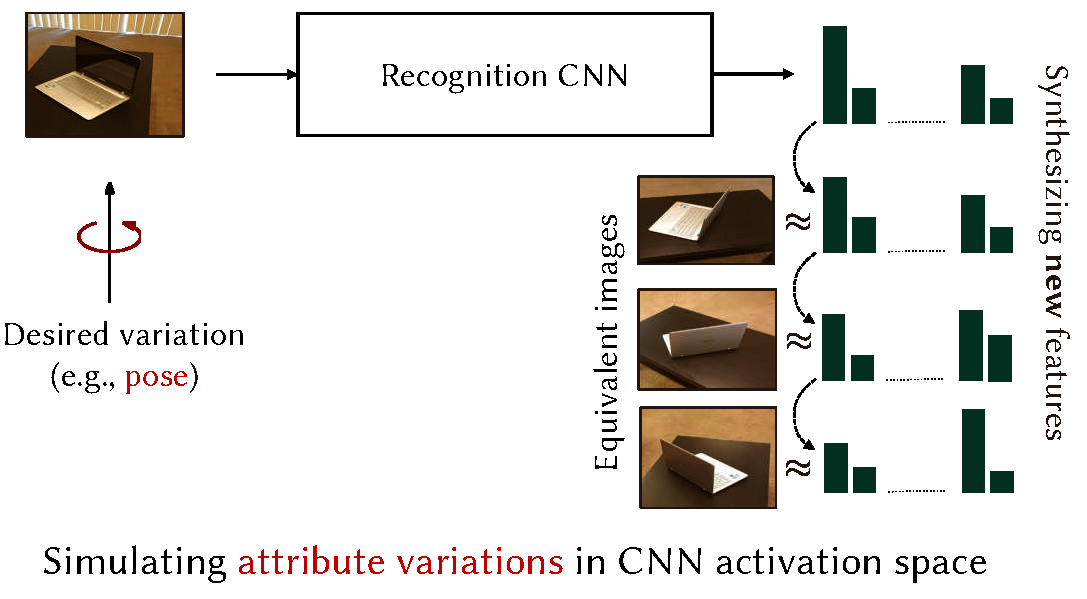 |
Attribute Guided Data Augmentation We propose a new approach to data synthesis called attribute guided augmentation. The underlying principle is to generate new examples from a given object image, by hallucinating changes in its attributes such as 3D pose and scene depth. The ability to synthsize non-trivial variations of data is found to be beneficial especially in few-shot learning scenarios. |
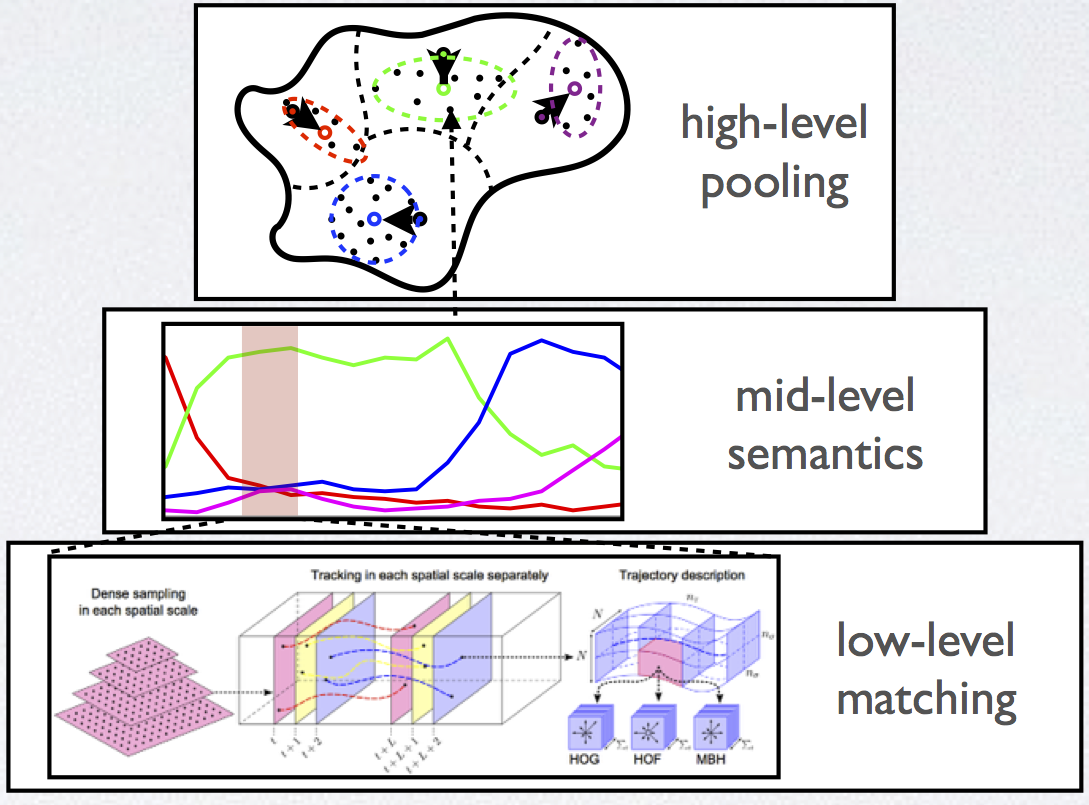 |
Complex Video Event Understantding We develop algorithms for complex events understanding by exploiting the video temporal strucutre modeling and semantic attribute representation, which aims to enable intelligent anaylsis, encoding and retrieval of informative and semantic content from open-source video data (e.g., those typical sequences on YouTube). |
 |
Person-Following UAVs We investigate the design of vision-based control algorithms for unmanned aerial vehicles (UAVs), so as to enable a UAV to autonomously follow a person. A new vision-based control architecture is proposed with the goals of 1) robustly following the user and 2) implementing following behaviors programmed by manipulation of visual patterns. |
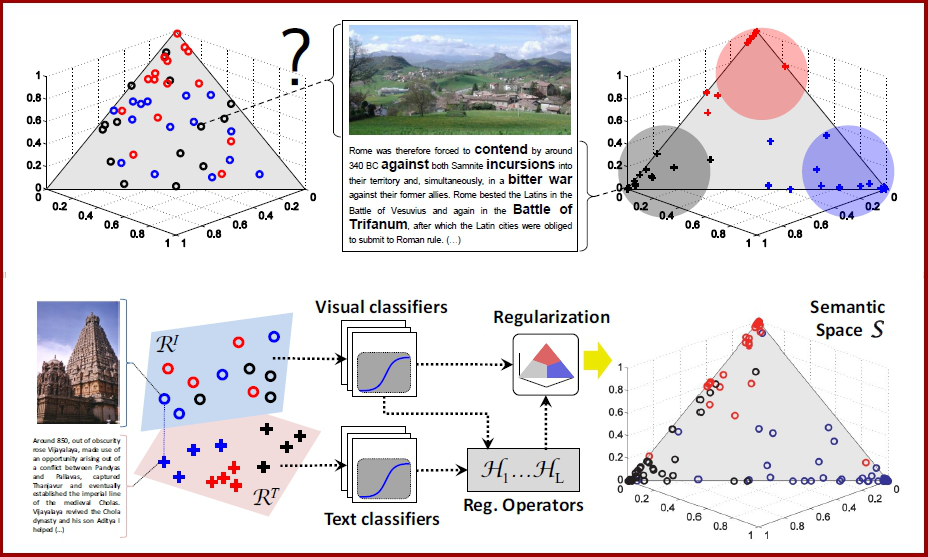 |
Regularization on (Content-Based) Image Retrieval Representation of image in semantic spaces is at the very core of many problems in Computer Vision. We provide an approach to transfer knowledge from texts associated with images in order to improve the accuracy of image semantic representations. Results are shown in the task of content-based image retrieval in three different datasets. |
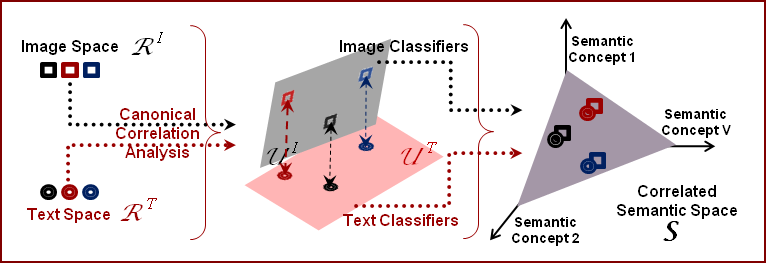 |
Cross-Modal Multimedia Retrieval The problem of joint modeling text and image components of multimedia documents is studied. Two hypotheses are investigated: that 1) there is a benefit to explicitly modeling correlations between the two components, and 2) this modeling is more effective in feature spaces with higher levels of abstraction. |
 |
Compressed-based Saliency Measure : In this work, we propose a simple and effective estimation method for video based on a new compressed-based domain feature. |
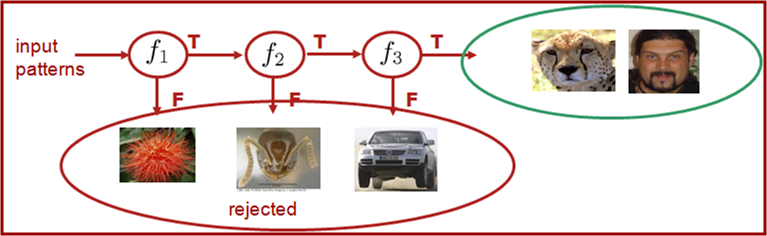 |
Training Detector Cascade: In this work, the problem of automatic and optimal design of embedded object detector cascades is considered. |
 |
Pedestrian Detection: The goal of this project is to build pedestrian detectors with low false-positive and high detection rates, which can operate in real-time. |
 |
Scaling Rapid Object Detection: The goal of this project is to design the algorithms needed to scale real-time object detection to thousands of objects. |
 |
TaylorBoost: First and Second Order Boosting Algorithms: In this project A new family of boosting algorithms, denoted, TaylorBoost, is proposed. |
 |
Multiclass Boosting: MCBoost: In this project the problem of multi-class boosting is considered. A new framework, based on multi-dimensional codewords and predictors is introduced. |
 |
Multi-Resolution Cascade: In this project, the problem of designing a multiclass detector cascade is considered. |
 |
Boosting Algorithms for Simultaneous Feature Extraction and Selection: In this project the problem of simultaneous feature extraction and selection, for classifier design, is considered. |
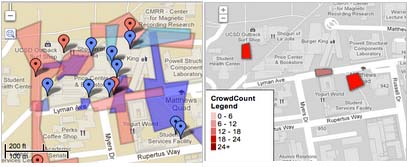 |
Automated and Distributed Crowd Analytics In this work, we developed a common experimental platform, which connects a distributed camera network with SVCL Analytics, specifically Crowd Counting. |
 |
Holistic Context Models for Visual Recognition In this work, we investigate an approach to context modeling based on the probability of co-occurrence of objects and scenes. This modeling is quite simple, and builds upon the availability of robust appearance classifiers. |
 |
Feedforward saliency network with a trainable neuron model We investigate the biological plausibility of statistical inference and learning, tuned to the statistics of natural images. It is shown that a rich family of statistical decision rules, confidence measures and risk estimates can be implemented with the computations to the standard neurophysiological model of V1. This is used to augment object recognition networks with top-down saliency. |
 |
Amorphous object detection in the wild A discriminant saliency network is applied to the problem of amorphous object detection. Amorphous objects are defined as objects without distinctive edge or shape structure. |
 |
Panda detection In this project, we utilize a deep learning framework, Caffe, for the purpose of detecting pandas. The reference caffe model is finetuned with images collected from the San Diego zoo panda cam. |
 |
Anomaly Detection: anomaly detection in crowded scenes using a mixture of dynamic textures representation. |
 |
Biological Plausibility of Discriminant Tracking: Psychophysics experiments and neurophysiological evidence to demonstrate the biological plausibility of the connections between discriminant center surround saliency and tracking. |
| Discriminant Tracking: a biologically inspired framework for tracking based on discriminant center surround saliency. | |
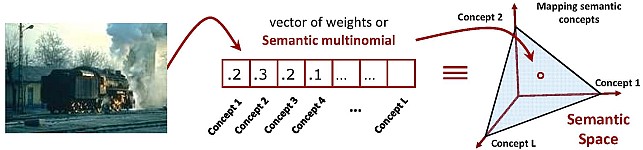 |
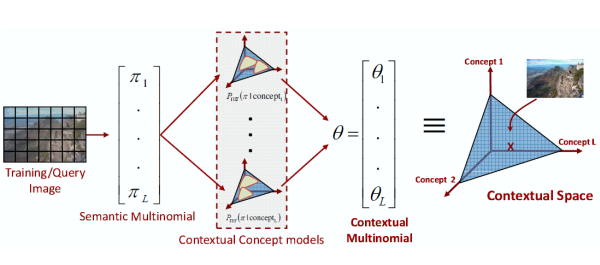
Semantic Image Representation: A novel image represenation is proposed where a semantic space is defined and images are represented on the semantic space as a posterior probability distribution for a given vocabulary of concepts. Benefits of semantic image represenation are illustrated through design of two visual recognition systems: Query by Semantic Example for the task of image retrieval and Low-dimensional Semantic Space Classification for scene classification. |
 |
Discriminant Hypothesis for Visual Saliency: a decision-theoretic formulation of visual saliency, its biological plausibility, and applications to computer vision. |
 |
Bottom-up Saliency and Its Biological Plausibility: biological plausibility of bottom-up saliency by combination of the discriminant hypothesis and center-surround operators. |
 |
Top-down Discriminant Saliency: learning discriminant salient features for visual recognition. |
 |
Understanding Video of Crowded Environments : motion segmentation and motion classification in video of crowded environments, such as pedestrian scenes and highway traffic. |
 |
Dynamic Textures: A family of generative stochastic dynamic texture models for analyzing motion. |
 |
Background Subtraction: Background subtraction in dynamic scenes. |
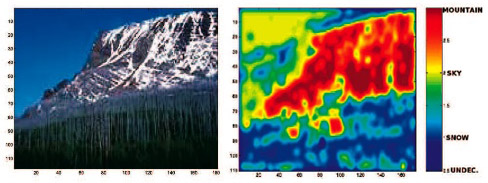 |
Semantic Image Annotation and Retrieval: automatically labeling images with content-based keywords, and image retrieval via automatic annotations. |
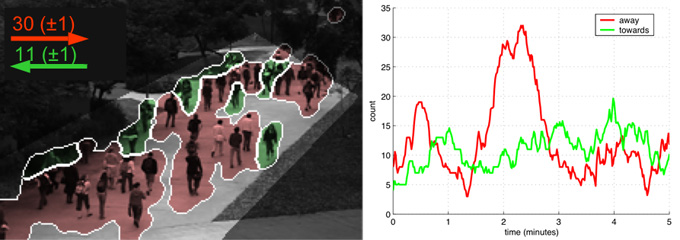 |
Pedestrian Crowd Counting: estimate the size of moving crowds in a privacy preserving manner, i.e. without people models or tracking. |
 |
Classification and Retrieval of Traffic Video: classification of traffic video using a generative probabilistic motion model and probabilistic kernel classifiers. |
 |
Motion Segmentation: robust segmentation of motion in video. |
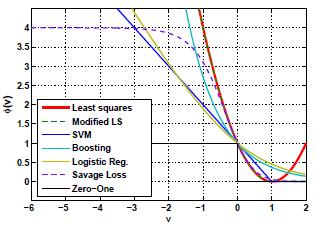 |
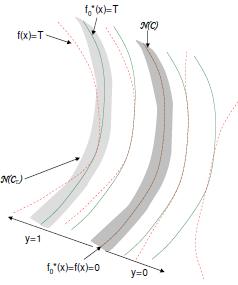
Classifier Loss Function Design: The design and theory of Bayes consistent loss functions and classifiers with applications. |
 |
Real-Time Object Detection Cascades: Real-time face, car, pedestrian and logo detection in images. |
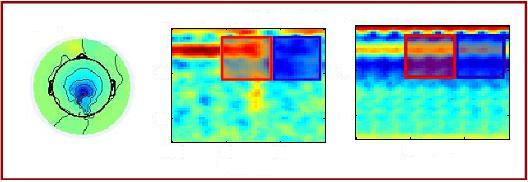 |
Real-Time EEG Surprise Signal Detection: Cost sensitive boosting and real-time detection cascades for EEG surprise signal detection. |
 |
Cost Sensitive Learning: The design and theory of cost sensitive classifiers with applications. |
 |
Image compression using Object-based Regions of Interest: learning ROI masks for image and video coding at very low bit-rates |
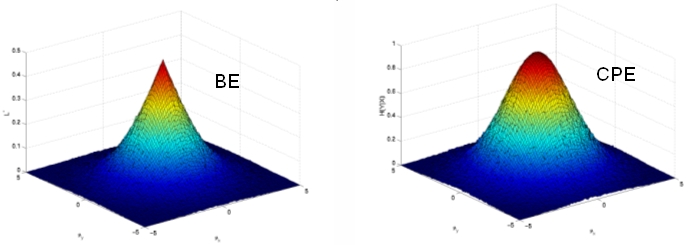 |
Optimal Features for Large-scale Visual Recognition: learning algorithms for feature design that are optimal, in the minimum probability of error sense, and scalable in the number of visual classes. |
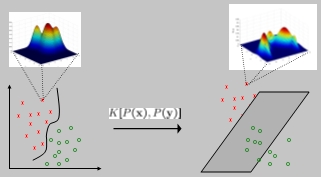 |
Probabilistic Kernel Classifiers: design of kernels functions between probability densities. |
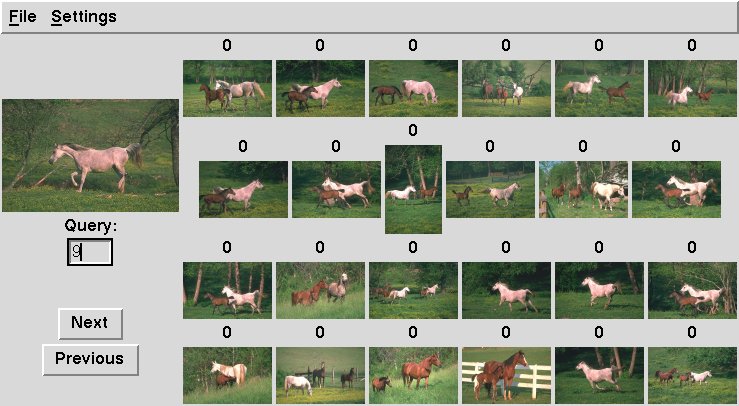 |
Minimum Probability of Error Image Retrieval: optimal search of large image collections with content-based queries. |
 |
Semantic Image Classification: augmenting retrieval systems with understanding of image semantics. |
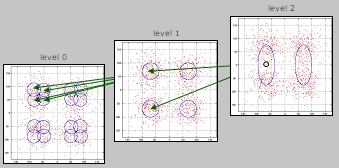 |
Learning Mixture Hierarchies: learning hierarchical mixture models for efficient classifier design, image indexing, and semantic classification hierarchies. |
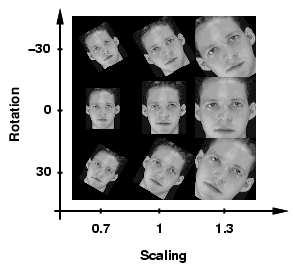 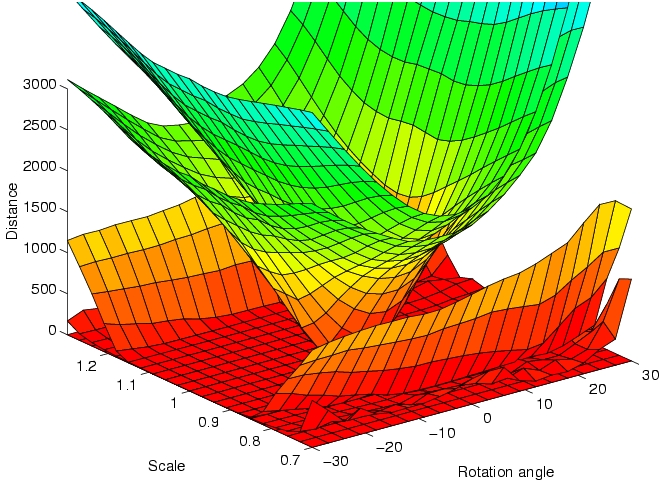 |
Measuring Image Manifold Distances: image similarity measures that are invariant to spatial transformations. |
  |
Motion Analysis: motion models and estimation algorithms for segmentation, mosaicking, and layered representations. |
 |
Modeling the Structure of Video: statistical models of video structure and Bayesian inference procedures for improved parsing and semantic classification. |
![]()
Copyright @ 2007 www.svcl.ucsd.edu