![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Semantic Image Annotation and Retrieval | |
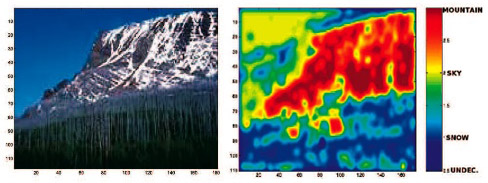
|
|
|
Content-based image retrieval, the problem of searching large image repositories according to their content, has been the subject of a significant amount of computer vision research in the recent past. While early retrieval architectures were based on the query-by-example paradigm, which formulates image retrieval as the search for the best database match to a user-provided query image, it was quickly realized that the design of fully functional retrieval systems would require support for semantic queries. These are systems where the database of images are annotated with semantic keywords, enabling the user to specify the query through a natural language description of the visual concepts of interest. This realization, combined with the cost of manual image labeling, generated significant interest in the problem of automatically extracting semantic descriptors from images.
The earliest efforts in the area were directed to the reliable extraction of specific semantics, e.g. differentiating indoor from outdoor scenes, cities from landscapes, and detecting trees, horses, or buildings, among others. These
efforts posed the problem of semantics extraction as one of supervised learning: a set of training images with and without the concept of interest was collected and a binary classifier trained to detect the concept of interest.
The classifier was then applied to all database of images which were, in this way, annotated with respect to the presence or absence of the concept.
More recently, there has been an effort to solve the problem in its full generality, by resorting to unsupervised learning. The basic idea is to introduce a set of latent variables that encode hidden states of the world, where each state defines a joint distribution on the space of semantic keywords and image appearance descriptors (in the form of local features computed over image neighborhoods). After the annotation model is learned, an image is annotated by finding the most likely keywords given the features of the image.
Both formulations of the semantic labeling problem have strong advantages and
disadvantages. In generic terms, unsupervised labeling leads to significantly more scalable (in database size and number of concepts of interest) training procedures, places much weaker demands on the quality of the manual annotations required to bootstrap learning, and produces a natural ranking of keywords for each new image to annotate. On the other hand, it does not explicitly treat semantics as image classes and, therefore, provides little guarantees that the semantic annotations are optimal in a recognition or retrieval sense. That is, instead of annotations that achieve the smallest probability of
retrieval error, it simply produces the ones that have largest joint likelihood under the assumed mixture model.
In this work we show that it is possible to combine the advantages of the two formulations through a slight reformulation of the supervised one. This consists of defining an M-ary classification problem where each of the semantic concepts of interest defines an image class. At annotation time, these classes all directly compete for the image to annotate, which no longer faces a sequence of independent binary tests. This supervised multiclass labeling (SML) obviously retains the classification and retrieval optimality of
the supervised formulation, but 1) produces a natural ordering of keywords at annotation time, and 2) eliminates the need to compute a "non-class" model for each of the semantic concepts of interest. In result, it has learning complexity equivalent to that of the unsupervised formulation and, like the latter, places much weaker requirements on the quality of manual labels than supervised OVA.
|
|
| Results: |
Here are both qualitative and quantitative results of the SML annotation algorithm.
|
| Databases: |
We have used the following data-sets for image annotation experiments. Please contact the respective people for information about obtaining the data:
|
| Publications: |
Supervised Learning of Semantic Classes for Image Annotation and Retrieval G. Carneiro, A. B. Chan, P. J. Moreno, and N. Vasconcelos IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 29(3), pp. 394-410, March 2006.© IEEE,[pdf] Formulating Semantic Image Annotation as a Supervised Learning Problem G. Carneiro and N. Vasconcelos Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, San Diego, 2005.© IEEE,[ps][pdf] A Database Centric View of Semantic Image Annotation and Retrieval G. Carneiro and N. Vasconcelos, Proceedings of ACM Conference on Research and Development in Information Retrieval (ACM SIGIR) Salvador, Brazil. 2005. [ps][pdf] Using Statistics to Search and Annotate Pictures: an Evaluation of Semantic Image Annotation and Retrieval on Large Databases A. B. Chan, P. J. Moreno, and N. Vasconcelos Proceedings of Joint Statistical Meetings (JSM), Seattle, 2006.[ps][pdf] Formulating Semantic Image Annotation as a Supervised Learning Problem G. Carneiro and N. Vasconcelos, Technical Report SVCL-TR-2004-03, December 2004. [ps][pdf] |
| Articles: |
Better, More Accurate Image Search Web Article, Technology Review, April 9, 2007. New Algorithms from UCSD Improve Automated Image Labeling Press Release, Jacobs School of Engineering, March 29, 2007. |
| Contact: | Nuno Vasconcelos |
![]()
©
SVCL