
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| Attribute Guided Data Augmentation | |
|
|
|
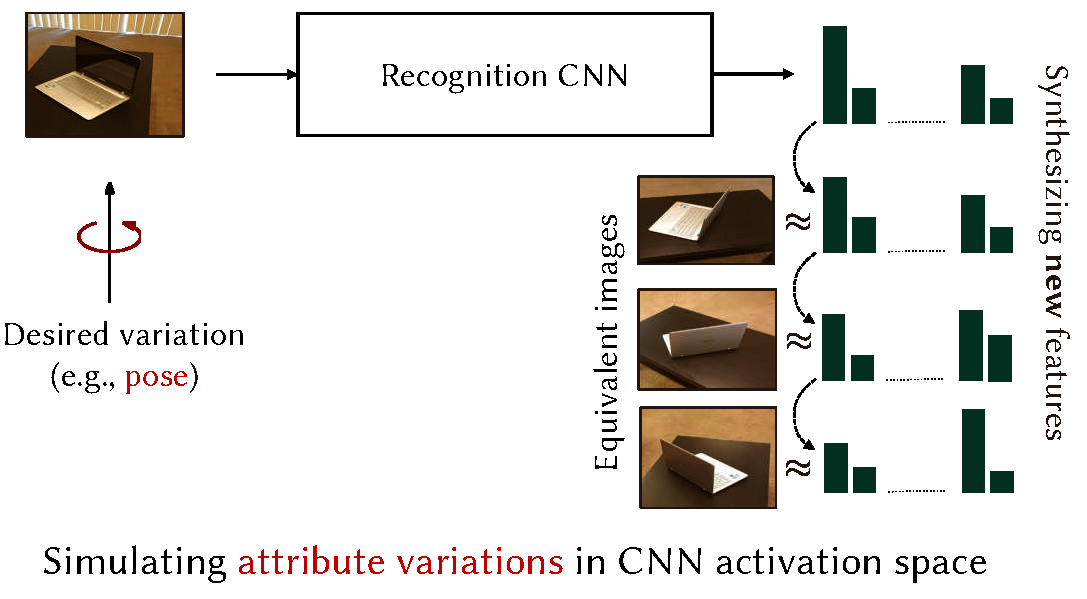
We propose a new approach to data augmentation, which we refer to as Attribute-Guided Augmentation (AGA), where synthetic data points are generated by hallucinating variations in attributes of real images. Standard methods of data augmentation produce somewhat trivial copies of images using operations such as cropping, in-plane rotation or addition of noise. Their impact on modern classifiers has, therefore, been marginal. Some recent proposals of data augmentation introduce more complex variations in image space with the help of 3D rendering and blending to create synthetic images. However, these methods depend on the availability of trained 3D CAD models or extensive 3D capture data making them unscalable. The proposed AGA, in contrast, is a deep learning based method that trains on a conventional vision dataset of images labeled with visual categories and their attributes. Our objective is to learn a network that, transforms an image in a predefined feature space, such that a particular quantifiable visual attribute of this image changes to a specified value. An example illustrating the process is shown in the figure above. Given an image of a "laptop", the system maps it into multiple synthetic data points in a CNN induced feature space, such that each point corresponds to a specified change in the "pose" attribute of the original laptop example. |
|
|
|
|
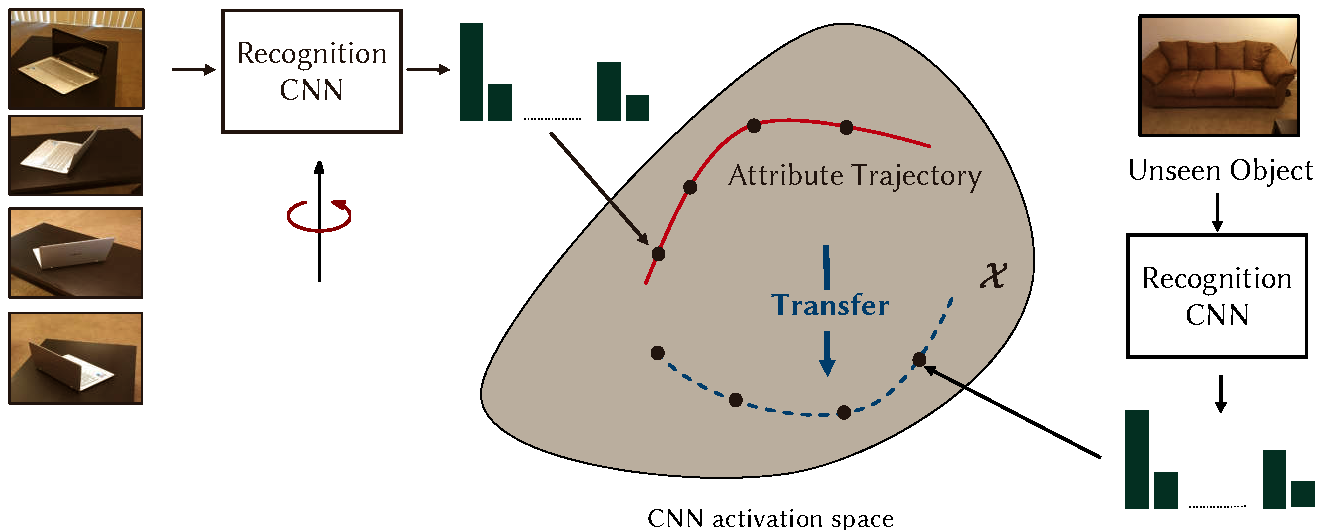
AGA can be formulated as an instance of attribute trajectory transfer, a process where learned trajectories of variations in a desired attribute, e.g. pose are transferred to a new example in order to imagine similar variations in it. Learning a trajectory of attributes, ideally requires an image sequence that depicts a class instance (e.g. the laptop in the image above) captured while undergoing all variations of an attribute (e.g. pose). A trajectory can be learned in an invariant feature space, such as the space of activations of an object recognition CNN. Data points synthesized via AGA's trajectory transfer would benefit from the discriminative nature of this space. The AGA framework is, therefore, a natural enahnacement for CNN based tranfer learning problems that are often faced with data constraints. |
|
|
|
|
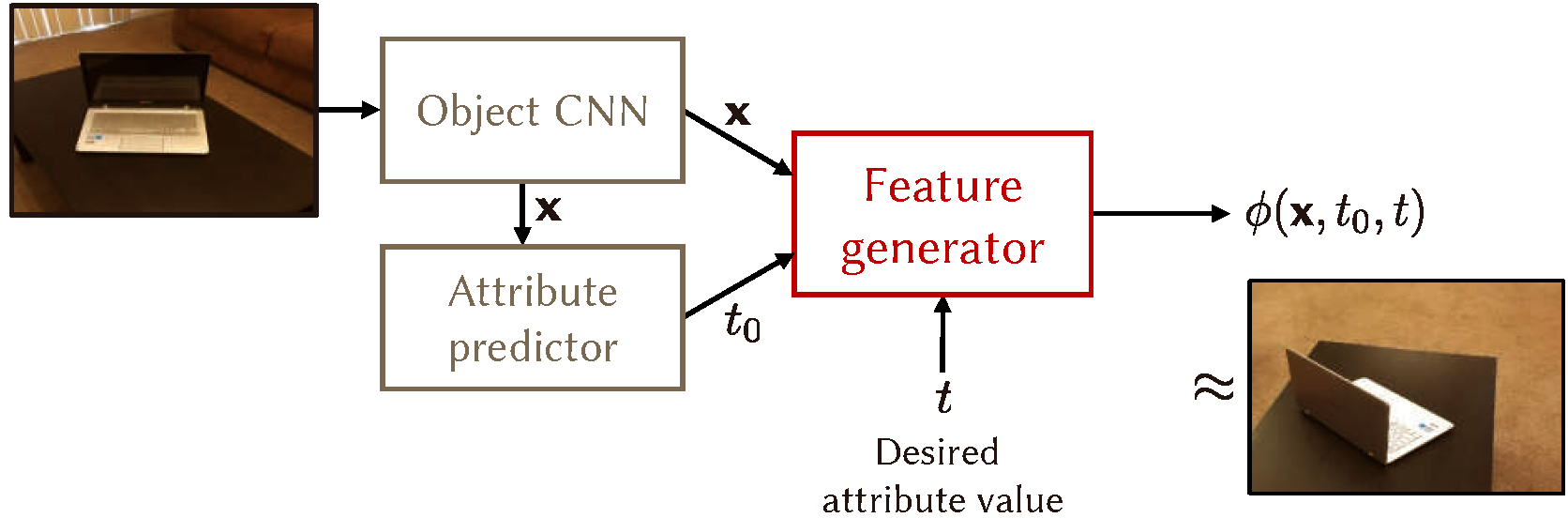
Trajectory transfer is difficult to achieve, in practice, because it requires a data set of image sequences in place of images, where each sequence depicts an object instance captured under multiple attribute values (e.g. a chair in all poses). Learning and transfer of attribute trajectories in the absence of such extensive corpora, it is not very straight-forward. To overcome this problem, and train AGA with standard datasets of labeled images, we propose a technique of attribute guided extrapolation which is implemented using the architecture shown above. In the feature space of an object CNN, we train an attribute regressor which induces a scalar measure. Given an object image, the regressor predicts its attribute value (e.g. pose). We then train a feature synthesizer module which accepts the image representation, and modifies it so that its current attribute value changes to a desired scalar. The desired change can be verified by the trained attribute regressor. To train the feature regressor, we do not require a sequence or even a pair of images of any given object. The regressor learns to modify a single available image (view) of any object by traversing the feature space, guided only by the attribute value (a scalar). The solution, therefore, is referred to as attribute guided extrapolation. To inspect the quality of AGA synthezed data points we use them for one-shot and few-shot transfer learning. The augmentation system is trained on 19 populous object classes of SUN RGBD dataset. For one-shot and few-shot learning experiments we use separate disjoint subset of the same dataset (denoted T1 and T2 in paper) for object recognition. Results show that our method succesfuly improves both one-shot and few-shot baselines by significant margins. |
|
| Presentation: | [Slides][Video by CvF] |
| Database: |
The AGA system was trained and evaluated on the SUN RGBD dataset using object category labels, bounding boxes and 3D depth and pose attribute labels:
|
| Publications: |
Attribute Guided Data Augmentation
M. Dixit, R. Kwitt, M. Niethammer, N. Vasconcelos to be submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence, © IEEE [pdf coming soon] [code coming soon] |
|
AGA: Attribute-Guided Augmentation M. Dixit, R. Kwitt, M. Niethammer, N. Vasconcelos In, IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, July 2017 © IEEE [pdf][code on github] | |
| Contact: | Mandar Dixit, Roland Kwitt, Nuno Vasconcelos |
![]()
©
SVCL