![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Scene Classification on Semantic Spaces | |
|
|
|
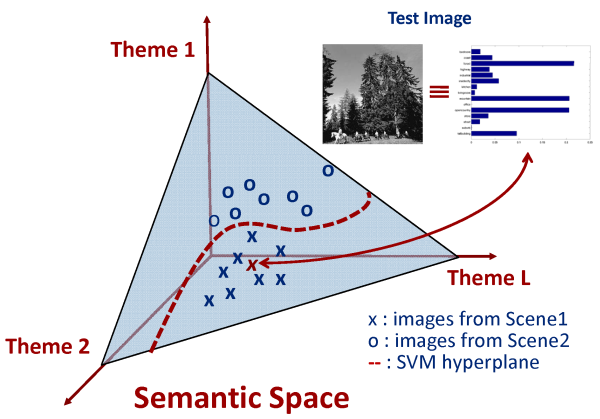
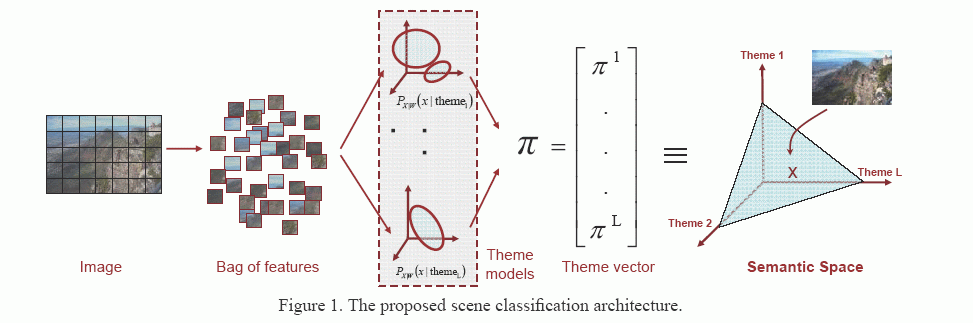
Scene classification is an important problem for computer vision, and has received considerable attention in the recent past. It differs from the conventional object detection/ classification, to the extent that a scene is composed of several entities often organized in an unpredictable layout Early efforts at scene classification targeted binary problems, such as distinguishing indoor from outdoor scenes etc. Subsequent research was inspired by the literature on human perception. More recently, there has been an effort to solve the problem in greater generality, through design of techniques capable of classifying relatively large number of scene categories. These methods tend to rely on local region descriptors, modeling an image as an order less collection of descriptors, commonly known as the "bag-of- features". The space of local region descriptors is then quantized, based on some clustering mechanism, and the mean vectors of these clusters, commonly known as "visterms" are chosen as their representatives. The representation of an image in this quantized space, is referred to as the "bag-of-visterms" representation. A set of cluster means, or visterms, forms a codebook, and a scene is characterized as a frequency vector over the visterms in the codebook. This representation is motivated by the time-tested bag-of-words model, widely used in text-retrieval. Lately, various extensions of this basic "bag-ofvisterms" model have been proposed. All such methods aim to provide a compact lower dimensional representation using some intermediate characterization on a latent space, commonly known as the intermediate "theme" or "topic" representation. The rationale is that images which share frequently co-occurring visterms have similar representation in the latent space, even if they have no visterms in common. This leads to representations robust to the problems of polysemy - a single visterm may represent different scene content, and synonymy - different visterms may represent the same content. It also helps to remove the redundancy that may be present in the basic bag-of-visterms model, and provides a semantically more meaningful image representation. Moreover, a lower dimensional latent space speeds up computation: for example, the time complexity of a Support Vector Machine (SVM) is linear in the dimension of the feature space. Finally, it is unclear that the success of the basic bag-of-visterms model would scale to very large problems, containing both large image corpuses and a large number of scene categories. Infact latent models have not yet been shown to be competitive with the flat bag-of-visterms representation. In this paper we propose an alternative solution. Like the latent model approaches, we introduce an intermediate space, based on a low dimensional semantic "theme" representation. However, instead of learning the themes in an unsupervised manner, from the "bag-of-visterms" representation, the semantic themes are explicitly defined, and the images are casually annotated with respect to their presence. This can always be done since, in the absence of thematic annotations, the themes can be made equal to the class labels, which are always available. The number of semantic themes used defines the dimensionality of the intermediate theme space, henceforth referred to as semantic space. Each theme induces a probability density on the space of low-level features, and the image is represented as the vector of posterior theme probabilities. An implementation of this approach is presented and compared to existing algorithms on benchmark datasets. It is shown that the proposed low dimensional representation correlates well with human scene understanding, captures theme cooccurrences without explicit training, outperforms the unsupervised latent-space approaches, and achieves performance close to the state of the art, previously only accessible with the flat bag-of-visterms representation, using a much higher dimensional image representation. |
|
| |
| Results: |
Quantitative results (Perfomance measures) Some examples of scene classification |
| Poster: | Scene Classification |
| Databases: |
We have used the following data-sets for the scene classification experiments. Please contact the respective people for information about obtaining the data:
|
| Publications: |
Scene Classification with Low-dimensional Semantic Spaces and Weak Supervision N. Rasiwasia and N. Vasconcelos. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, June 2008. �IEEE, [ps][pdf] |
| Contact: | Nuno Vasconcelos, Nikhil Rasiwasia |
![]()
©
SVCL