
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| Bag-of-Semantics for Semantic Transfer | |
|
|
|
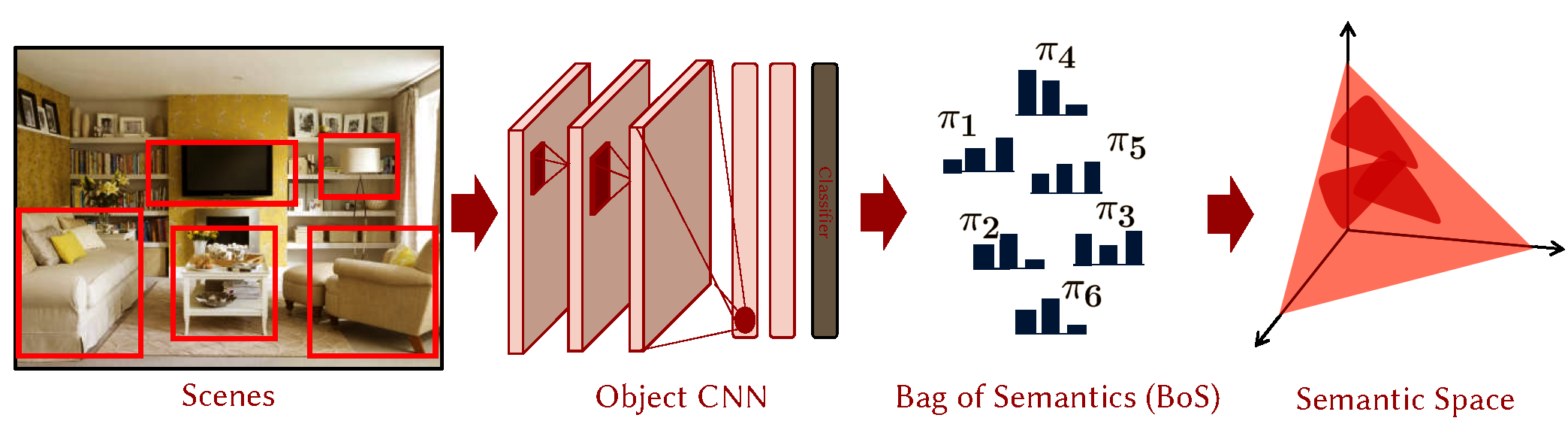
A scene is often described as a collection of "objects" and "stuff" appearing in unpredictable layouts. Images of a scene can, therefore, be described as a collections of object recognition scores obtained from their patches or regions. We refer to this as a Bag of Semantics (BoS) representation of scenes. Descriptors in a BoS, represent local semantic information, such as probability of occurrence of a set of objects within an image region. In this work, we use sophisticated object recognizers such as ImageNet trained object recognition convolutional neural networks (CNNs) to generate a scene BoS. A semantic descriptor generated by a CNN is a probability multinomial that resides on a semantic simplex. A collection of multinomial vectors produced by the CNN for a scene image is then embedded into a fixed length representation using a popular descriptor encoding and pooling method called Fisher vectors (FV). A Fisher vector obtained from a BoS, a semantic Fisher vector for short, is then used with a linear SVM for scene classification. The proposed semantic FV is a representation obtained using a learned classifier of objects (the ImageNet CNN) for holistic scene level inference. The resulting scene classifier is, therefore, a unique example of learners that facilitate knowledge transfer across visual domains (object to scenes). |
|
|
|
|
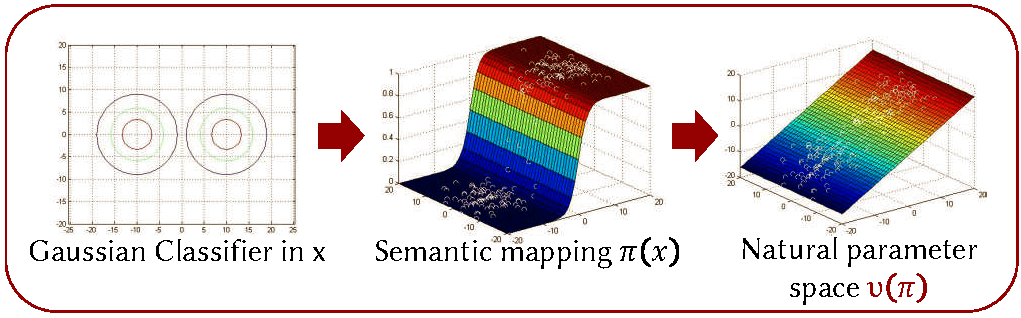
In vision, image descriptors are often assumed i.i.d. samples from a generative distribution, such as a Gaussian Mixture model (GMM). An FV is obtained as a scaled gradient of image log-likelihood under such a mixture. Summarizing a BoS with an appropriate FV, however, is not as straight forward as obtaining FVs of other descriptors. This is beacuse the semantic descriptors that constitute a BoS reside in a highly non-Euclidean simplex. We show that neither a Gaussian mixture nor a Dirichlet mixture is capable of modeling a distribution on the simplex and producing an FV that carries all the discriminative information available within the BoS. Transforming the semantic multinomials, instead, with log like non-linearities and obtaining a GMM FV in this space results in a very good scene classification performance. The reasons for success of log-probabilities is that the log transformation projects a multinomial into a natural parameter space which is inherenly Euclidean and therefore allows modeling of descriptor distributions with a simple Gaussian mixture. In fact, we show that the space of activations of the softmax layer in a CNN is a natural parameter space of multinomials, and an FV derived from it performs even better than with log probabilities. Therefor, to obtain a robust semantic FV using an ImageNet CNN, one should simply remove the softmax layer of the network and compute a standard GMM FV in the space of natural parameter outputs. |
|
|
|
|
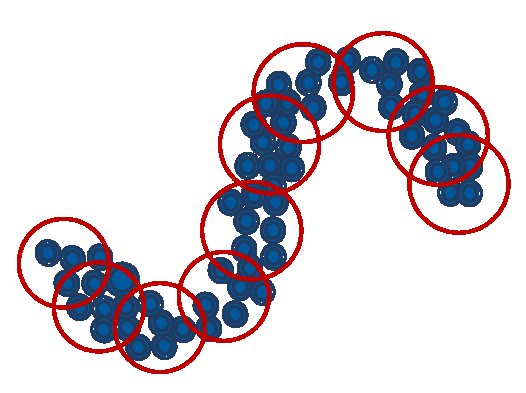
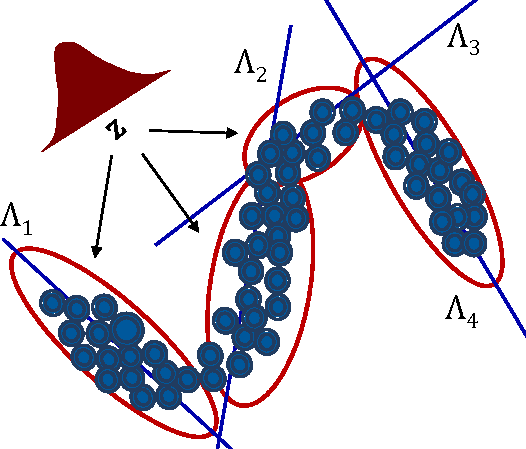
Despite its good performance, a classical FV derives from a Gaussian mixture model with diagonal covariance matrices. In a high dimensional space of CNN activations (e.g. semantics or natural parameters) using a variance GMM for modeling is an inefficient approach. As shown in the figure above, a variance GMM (left) may require an unnecessarily large number of Gaussians to cover a non-linear data manifold. On the contrary, using a GMM that can model local covariances is much more economical and may even produce better FVs. One way of modeling approximate covariance is using mixture of factor analyzer (MFA). An MFA projects the data in local linear subspaces that approximate the data manifold more efficiently and economically as illustrated in the figure (right). An FV derived from the MFA model is shown to capture rich covariance statistics which are unavailable to a variance GMM derived conventional FV. We show that semantic FVs derived from an MFA in natural parameter space achieves much better performance compared to semantic FVs obtained from a variance GMM. The classifier built using ImageNet CNN's natural parameters activations and an MFA FV is shown to be state-of-the-art for transfer based scene recognition on challenging baselines like SUN and MIT Indoor. |
|
| Some Examples: | [Correct Classification][Mis Classification] |
| Datasets: |
Semantic transfer based scene classifier was trained and evaluated on the MIT Indoor Scenes and SUN datasets:
|
| Publications: |
Bag-of-Semantics Representations for Object to Scene Transfer
M. Dixit, Y. Li, N. Vasconcelos to be submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence, © IEEE [coming soon] |
|
Object based Scene Representations using Fisher Scores of Local Subspace Projections M. Dixit, R. Kwitt, M. Niethammer, N. Vasconcelos In, Neural Information Processing Systems (NIPS), Barcelona, Spain, Dec. 2016 © IEEE [pdf] | |
|
Scene Classification with Semantic Fisher Vectors M. Dixit, S. Chen, D. Gao, N. Rasiwasia, N. Vasconcelos In, IEEE International Conf. on Computer Vision (CVPR), Boston, June. 2015 © IEEE [pdf] | |
| Contact: | Mandar Dixit, Nuno Vasconcelos |
![]()
©
SVCL