Dynamic Networks for Resource Constrained Image Recognition
Overview
Deep learning has brought remarkable improvement for the performance of image recognition tasks. However, the resource limitation forms a big obstacle for the real application of deep learning. Two types of resource constraints- limited machine's computing power and lack of annotated data are considered. Compared to leveraging a large static network formed by input independent blocks, we try to overcome the issues of resource limitation with a more effective architecture by proposing a series of dynamic neural networks with input dependent blocks. For the tasks with constrained computational resources, we first consider the multi-domain learning problem, which requires a single framework to perform well on multiple datasets for image classification. CovNorm is proposed to dynamically project a common feature to different feature spaces according to the dataset ID by consuming tiny numbers of extra parameters and computation. Then a large scale image recognition problem under different computational resources is explored. Dynamic Convolution Decomposition (DCD) is proposed for the machines with computing power from the order of 100 MFLOPs to 10 GFLOPs while MicroNet is designed to be applied on the machines with the computational cost far below 100 MFLOPs. Empowered by the dynamic architecture, both DCD and MicroNet achieve a significant improvement within their working scope. For the issue of lacking annotated data, we work on the domain adaptation tasks, where the dataset is partially labeled and a domain gap exists between the labeled data (source domain) and the unlabeled data (target domain). We start by considering a relatively simple case with a single source and single target domain on semantic segmentation. A bidirectional learning (BDL) framework is designed and it reveals the synergy of several key factors, i.e., adversarial learning and self-training for domain adaptation. Based on the techniques given by BDL and the power of dynamic networks, a more complex problem- multi-source domain adaptation is investigated. Dynamic residual transfer (DRT) is presented and shows tremendous improvement for the adaptation performance compared to its static version. It confirms the effectiveness of dynamic networks for the image recognition problem when the amount of annotated data is limited.
Projects
A Domain-Wise Dynamic Framework for Multi-Domain Learning
The multi-domain learning asks for a generic framework to do classification job on different datasets (domains). In order to avoid building a model per dataset, a series of adaptive layers are dynamically induced according to each target dataset and a novel procedure, denoted covariance normalization (CovNorm), is proposed to reduce its parameters. CovNorm is applied per convolutional layer to convert the domain-common feature to the domain-specific feature. It is a data driven method of fairly simple implementation, requiring two principal component analyzes (PCA) and fine-tuning of a mini-adaptation layer. Nevertheless, it is shown, both theoretically and experimentally, to have several advantages over previous approaches, such as batch normalization or geometric matrix approximations. One more benefit is that CovNorm can be deployed both when target datasets are available sequentially or simultaneously.
Sample-Wise Dynamic Framework for Large-Scale Image Recognition
This project further explores the power of CovNorm by deploying it on the large-scale image recognition and parametrize it in a sample-wise manner with an input dependent branch. The new framework is denoted as dynamic convolution decomposition (DCD). Surprisingly, it not only achieves an excellent performance on large-scale image classification dataset- ImageNet with different backbones but also successfully addresses the two issues, i.e., model redundancy and hardness of optimization, brought by the previous dynamic modules built on convolutional layers. More important, we reveal the fundamental reason that leads to these drawbacks mathematically for the previous methods, which is the application of dynamic attention over channel groups in a high dimensional latent space. And the proposed DCD can perfectly overcome this problem by applying dynamic channel fusion in a low dimensional space.
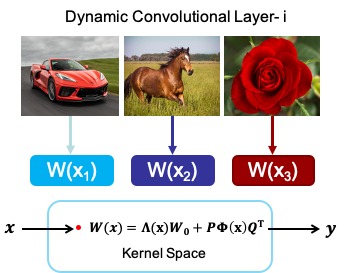
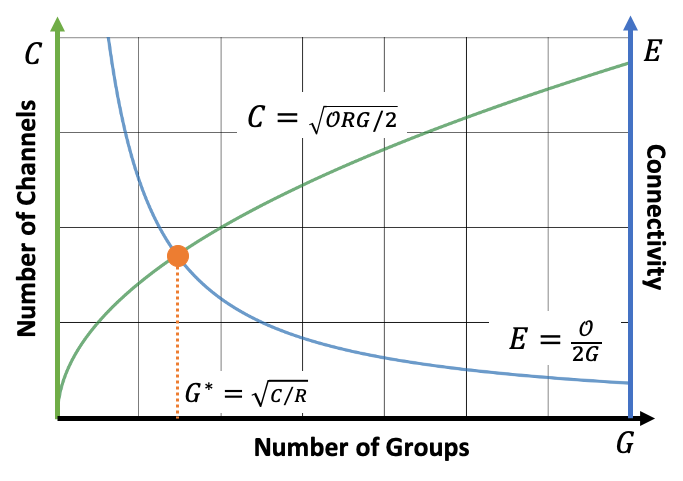
Large-Scale Image Recognition with Extremely Low FLOPs
The previously introduced dynamic operator is built on existing backbones, i.e., ResNet and MobileNet V2. They are mainly leveraged by the devices with computational budget ranging from the order of 100 MFLOPs to 10 GFLOPs. In order to extend the application of deep learning to some extreme cases of computational resources, e.g., below 10 MFLOPs, we present MicroNet. We handle the issue of extremely low FLOPs based upon two design principles: (a) avoiding the reduction of network width by lowering the node connectivity, and (b) compensating for the reduction of network depth by introducing more complex non-linearity per layer. First, we propose Micro-Factorized convolution to factorize both pointwise and depthwise convolutions into low rank matrices for a good tradeoff between the number of channels and input/output connectivity. Second, we propose a new activation function, named Dynamic Shift-Max, to improve the non-linearity via maxing out multiple dynamic fusions between an input feature map and its circular channel shift. The fusions are dynamic as their parameters are adapted to the input. Building upon Micro-Factorized convolution and Dynamic Shift-Max, a family of MicroNets achieve a significant performance gain over the state-of-the-art in the low FLOP regime for several recognition tasks, i.e., large scale image classification, object detection and keypoint detection.
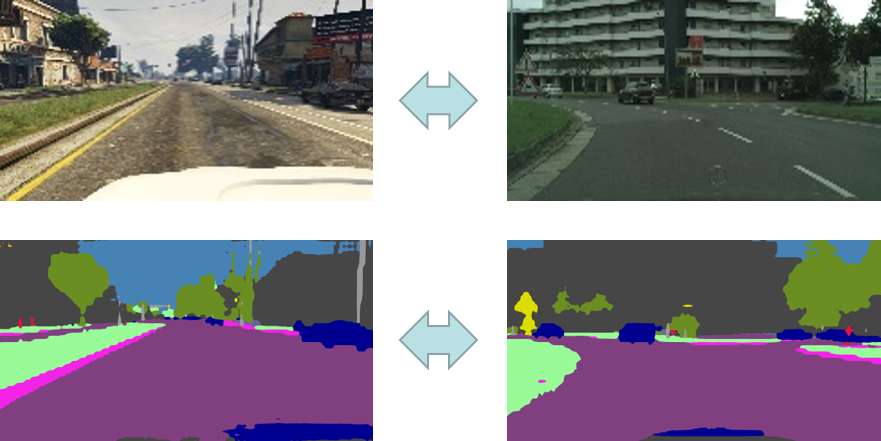
Bidirectional Learning Domain Adaptation on Semantic Segmentation
The annotated data is another critical type of resources for deep learning and domain adaptation is one of the key subjects to deal with the issue when the annotated data is lacking. Specifically, domain adaptation assumes the annotated data is restricted to some domains which are different to the domain of the unlabeled data that we care more about. This difference is denoted as domain discrepancy. In order to tackle the domain discrepancy, we propose a novel bidirectional learning framework. The framework is mainly designed for segmentation tasks and it contains two parts- image translation model and segmentation model. Using the bidirectional learning, the image translation model and the segmentation model can be learned alternatively and promote to each other. Furthermore, we propose a self-training algorithm to learn a better segmentation model and in return improve the image translation model. Experiments show that our method is superior to the state-of-the-art methods in domain adaptation of segmentation with a big margin. More critical, bidirecctional learning framework reveals that the synergy of image translation, segmentation model and self-training.
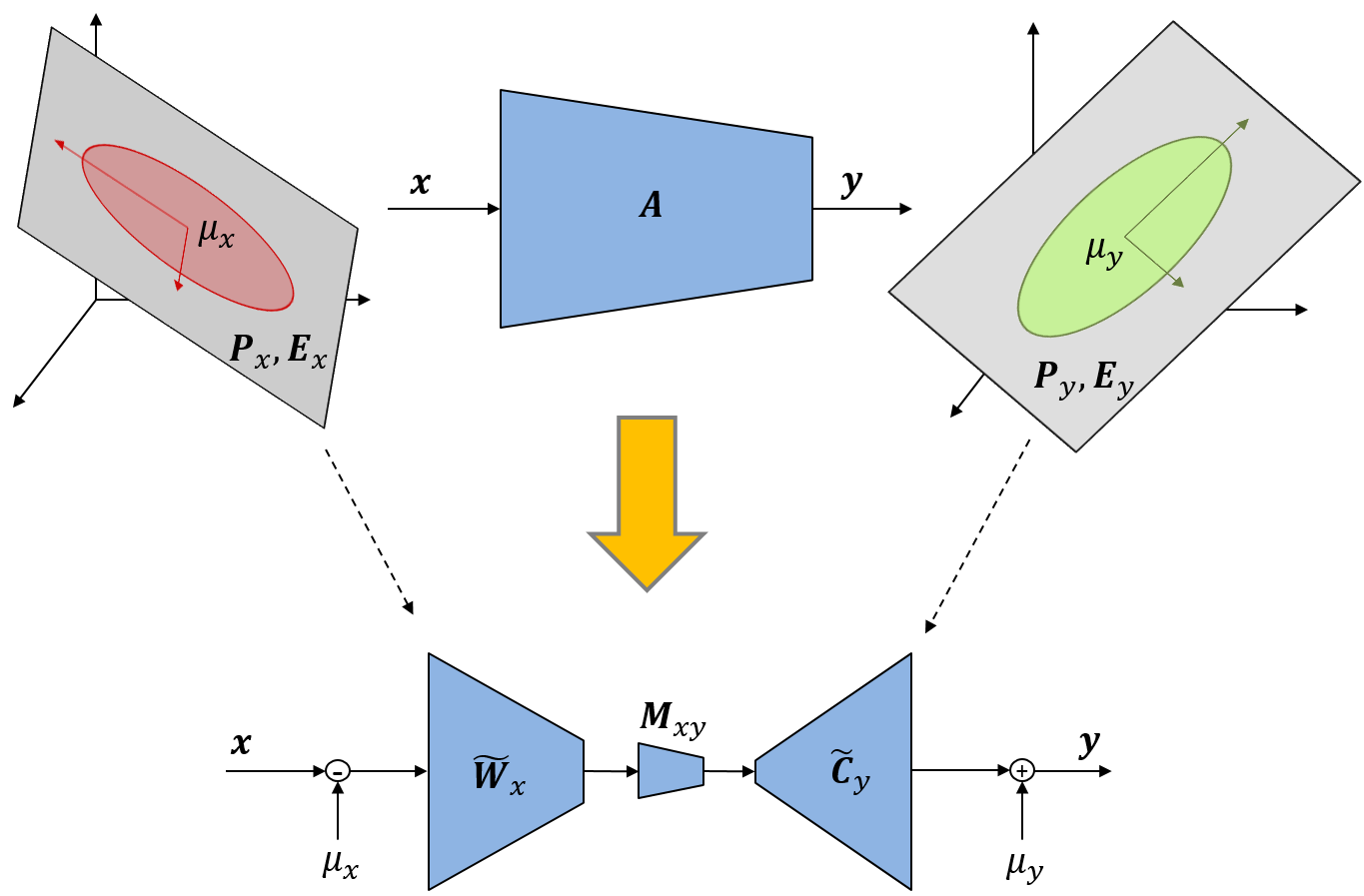
Dynamic Transfer for Multi-Source Domain Adaptation
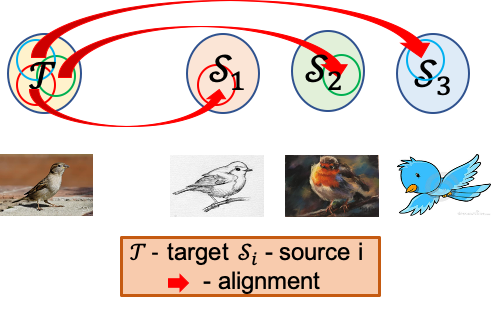
Motivated by the findings given by the bidirectional learning framework, a more complex domain adaptation task- multi-source domain adaptation is considered. The multi-source domain adaptation task considers the source domain as an union of images with various styles (domains). Recent works focus on learning a domain-agnostic model, of which the parameters are static. However, such a static model is difficult to handle conflicts across multiple domains, and suffers from a performance degradation in both source domains and target domain. Inspired by the success of dynamic networks for supervised cases, we present dynamic transfer to address domain conflicts. The key insight is that adapting model across domains is achieved via adapting model across samples. Thus, it breaks down source domain barriers and turns multi-source domains into a single-source domain. This also simplifies the alignment between source and target domains, as it only requires the target domain to be aligned with any part of the union of source domains. Furthermore, we find dynamic transfer can be simply modeled by aggregating residual matrices and a static convolution matrix.
Publications
Dynamic Neural Networks for Resource Constrained Image Recognition
Yunsheng Li
Ph.D. Thesis, University of California San Diego,
2021.
Dynamic Transfer for Multi-Source Domain Adaptation
Yunsheng Li, Lu Yuan, Yinpeng Chen, Pei Wang and Nuno Vasconcelos
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
2021.
MicroNet: Improving Image Recognition with Extremely Low FLOPs
Yunsheng Li, Yinpeng Chen, Xiyang Dai, Dongdong Chen, Mengchen Liu, Lu Yuan, Zicheng Liu, Lei Zhang and Nuno Vasconcelos
Proceedings of IEEE International Conference on Computer Vision (ICCV),
2021.
Revisiting Dynamic Convolution via Matrix Decomposition
Yunsheng Li, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Ye Yue, Lu Yuan, Zicheng Liu, Mei Chen and Nuno Vasconcelos
The Ninth International Conference on Learning Representations (ICLR),
2021.
Bidirectional Learning for Domain Adaptation of Semantic Segmentation
Yunsheng Li, Lu Yuan and Nuno Vasconcelos
Proceedings of IEEE International Conference on Computer Vision (CVPR),
2019.
Efficient Multi-Domain Learning by Covariance Normalization
Yunsheng Li and Nuno Vasconcelos
Proceedings of IEEE International Conference on Computer Vision (CVPR),
2019.
Acknowledgements
This work was partially funded by NSF awards IIS-1924937, IIS-2041009, and gifts from NVIDIA, Amazon and Qualcomm. We also acknowledge and thank the use of the Nautilus platform for some of the experiments in the papers above.