![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

| Modeling the Structure of Video | |
|
|
|
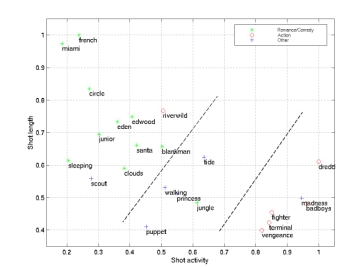
Today’s computers are highly effective at processing either numerical or textual data, but have very limited capabilities to process other data-types (e.g. audio, video, or even biological signals) in a sophisticated manner. The development of such capabilities is a perquisite for the development of systems capable of automatically filtering, retrieving, and parsing content. Because video production obeys various well established codes (see e.g. a large literature in film theory), video exhibits a significant amount of structure that can be exploited to achieve automatic understanding of its content. For example, close-ups are frequently used to convey emotion, while rapid editing is commonly used as a tool to create suspense. This project addresses the design of statistical models for video content. A Bayesian framework is adopted, where knowledge about the “film grammar” is 1) encoded in the form of prior probabilities for certain video attributes (e.g. scene duration) and 2) combined with measurements obtained from examples according to the principles of Bayesian inference (using Bayesian networks). These models have been shown to improve the performance of low-level video processing operations (e.g. shot segmentation) and have illustrated how classification of video into categories such as “action”, “romance”, or “comedy” can be achieved with relatively simple content descriptors. A movie classification system (BMoViES), capable of classifying scenes according to attributes such as "presence of close-ups", "amount of action", "set type", and "shot type" has been demonstrated.
|
|
| Selected Publications: |
|
| Demos/ Results: |
|
| Contact: | Nuno Vasconcelos |
![]()
©
SVCL