![]()
| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective
Students |
About | Internal |

Results for Query by Semantic Example |
|||||||||
|
This page contains the major results of experiments using Query by Semantic Example (QBSE) to perform image retrieval, and its comparison to Query by Visual Example (QBVE). If you have new results that you would like to add, contact Nuno Vasconcelos with the reference. |
|||||||||
|
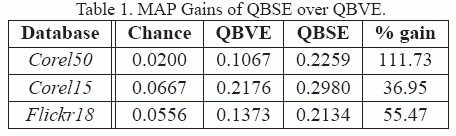
Evaluation ProtocolIn all cases, performance is measured with precision and recall, a classical measure of information retrieval performance, which is also widely used by the image retrieval community. Given a query and the top N database matches, also called as scope, if r of the retrieved objects are relevant (where relevant means belonging to the class of the query), and the total number of relevant objects in the database is R, then precision is defined as r/N, i.e., the percentage of N which are relevant and recall as r/R, which is the percentage of all relevant images contained in the retrieved set. Precision-recall is commonly summarized by the mean average precision (MAP). This consists of averaging the precision at the ranks where recall changes, and taking the mean over a set of queries. |
|||||||||
Databases | |||||||||
Performance Measures* | |||||||||
MAP accross all databases
| |||||||||
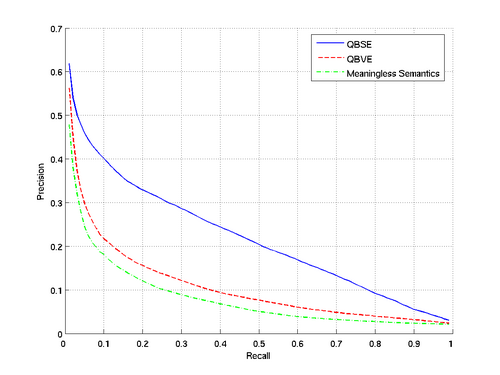
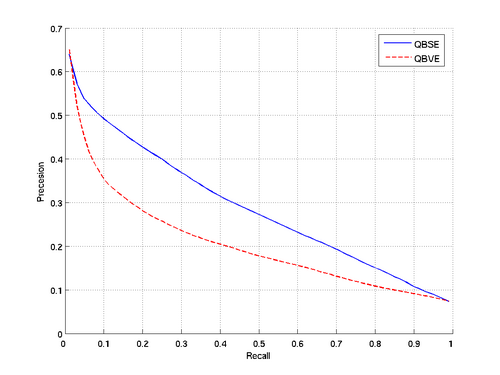
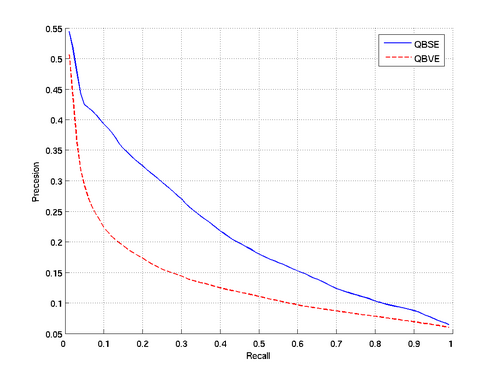
Precision-Recall Curves for the databases#
| |||||||||
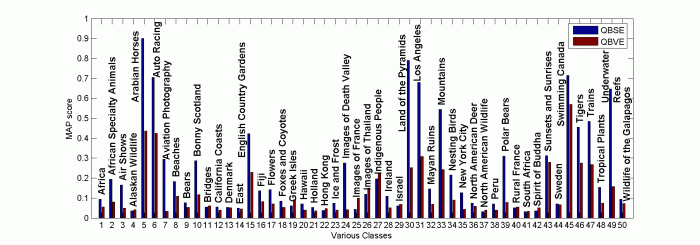
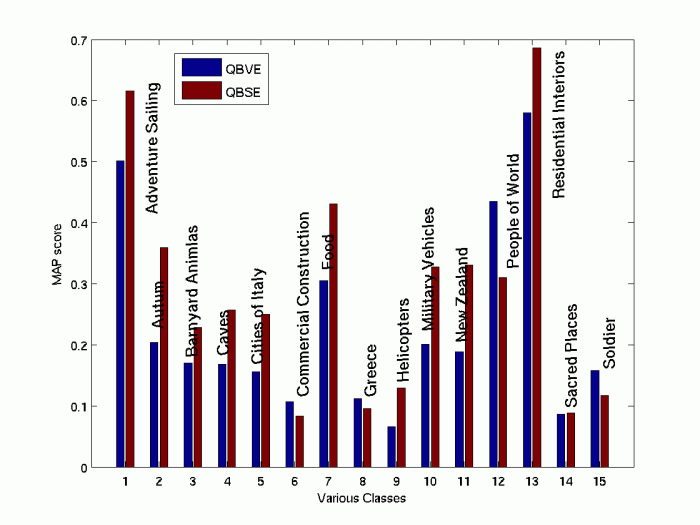
MAP accross different Classes
| |||||||||
MAP as a function of query cardinality for multiple query images for Corel50
| |||||||||
(*)All Results are calculated using multiple query images for both QBSE and QBVE. | |||||||||
![]()
©
SVCL