| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| SavageBoost | ||||||||||
|
||||||||||
|
The machine learning problem of classifier design is studied from the perspective
of probability elicitation, in statistics. This shows that the standard approach of
proceeding from the specification of a loss, to the minimization of conditional
risk is overly restrictive. It is shown that a better alternative is to start from the
specification of a functional form for the minimum conditional risk, and derive
the loss function. This has various consequences of practical interest, such as
showing that 1) the widely adopted practice of relying on convex loss functions is
unnecessary, and 2) many new losses can be derived for classification problems.
These points are illustrated by the derivation of a new loss which is not convex,
but does not compromise the computational tractability of classifier design, and
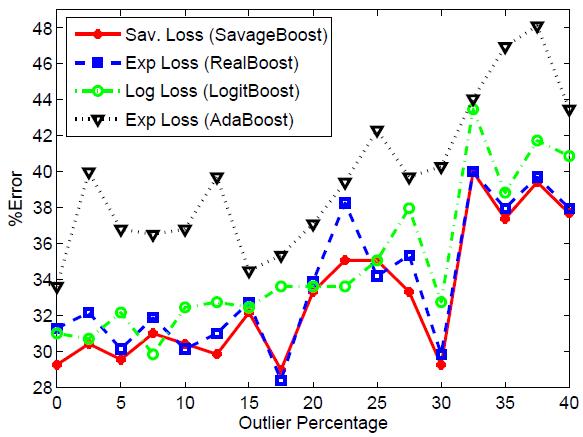
is robust to the contamination of data with outliers. A new boosting algorithm,
SavageBoost, is derived for the minimization of this loss. Experimental results
show that it is indeed less sensitive to outliers than conventional methods, such as
Ada, Real, or LogitBoost, and converges in fewer iterations.
| ||||||||||
![]()
Copyright @ 2007
www.svcl.ucsd.edu