| Home | People | Research | Publications | Demos |
| News | Jobs |
Prospective Students |
About | Internal |

| Cost Sensitive SVM | ||||||||||
|
||||||||||
|
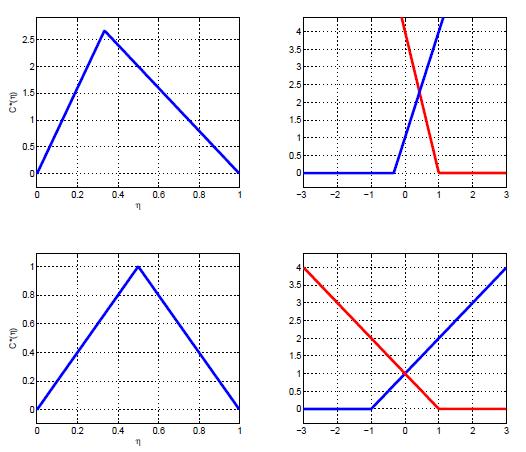
A new procedure for learning cost-sensitive
SVM classifiers is proposed. The SVM hinge
loss is extended to the cost sensitive setting, and
the cost-sensitive SVM is derived as the minimizer
of the associated risk. The extension of
the hinge loss draws on recent connections between
risk minimization and probability elicitation.
These connections are generalized to costsensitive
classification, in a manner that guarantees
consistency with the cost-sensitive Bayes
risk, and associated Bayes decision rule. This ensures
that optimal decision rules, under the new
hinge loss, implement the Bayes-optimal costsensitive
classification boundary. Minimization
of the new hinge loss is shown to be a generalization
of the classic SVMoptimization problem,
and can be solved by identical procedures. The
resulting algorithm avoids the shortcomings of
previous approaches to cost-sensitive SVM design,
and has superior experimental performance.
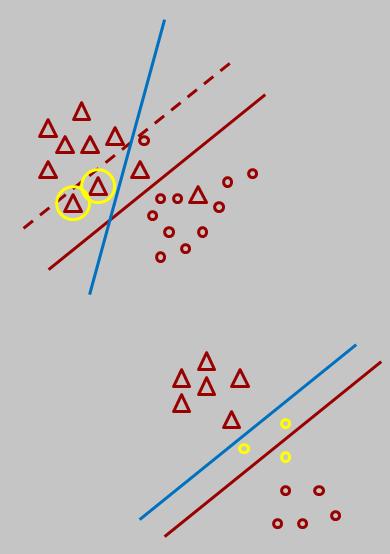
The performance of the CS-SVM was evaluated on the German
Credit data set. This dataset has 700 examples of good credit customers
and 300 examples of bad credit customers. Each example
is described by 24 attributes, and the goal is to identify bad
costumers, to be denied credit. This data set is particularly
interesting for cost-sensitive learning because it provides a
cost matrix for the different types of errors. Classifying a
good credit customer as bad (a false-positive) incurs a loss
of 1. Classifying a bad credit customer as good (a miss)
incurs a loss of 5. Using the CS-SVM algorithm results in a substantial reduction of cost by 37.36%.
| ||||||||||
![]()
Copyright @ 2007
www.svcl.ucsd.edu