Overview
A unified deep neural network, denoted the multi-scale CNN (MS-CNN), is proposed for fast multi-scale object detection. The MSCNN consists of a proposal sub-network and a detection sub-network. In the proposal sub-network, detection is performed at multiple output layers, so that receptive fields match objects of different scales. These complementary scale-specific detectors are combined to produce a strong multi-scale object detector. The unified network is learned end-to-end, by optimizing a multi-task loss. Feature upsampling by deconvolution is also explored, as an alternative to input upsampling, to reduce the memory and computation costs. State-of-the-art object detection performance, at up to 15 fps, is reported on datasets, such as KITTI and Caltech, containing a substantial number of small objects.
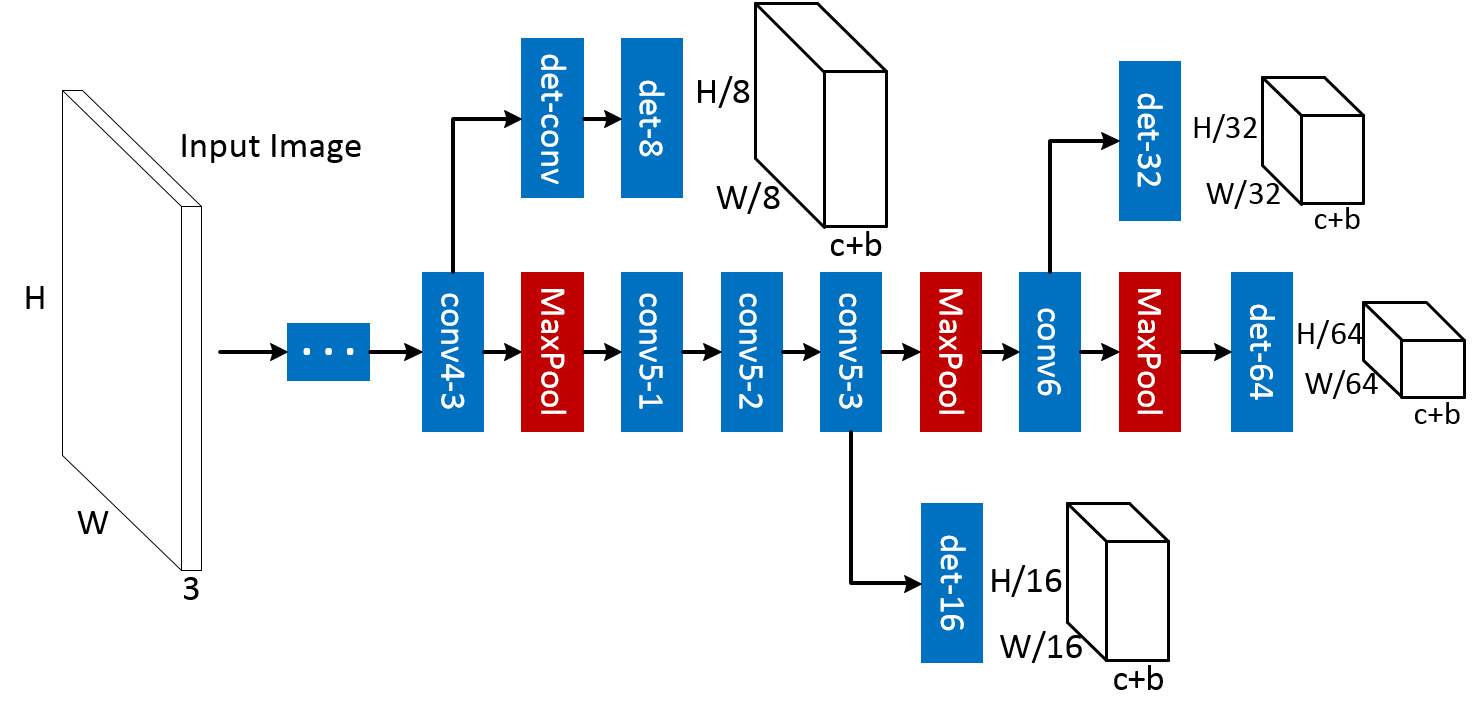
The detailed architecture of the MS-CNN proposal network is shown in the above figure. The network detects objects through several detection branches. The results by all detection branches are simply grouped together as the final proposal detections. The network has a standard CNN trunk, depicted in the center of the figure, and a set of output branches, which emanate from different layers of the trunk. These branches consist of a single detection layer.
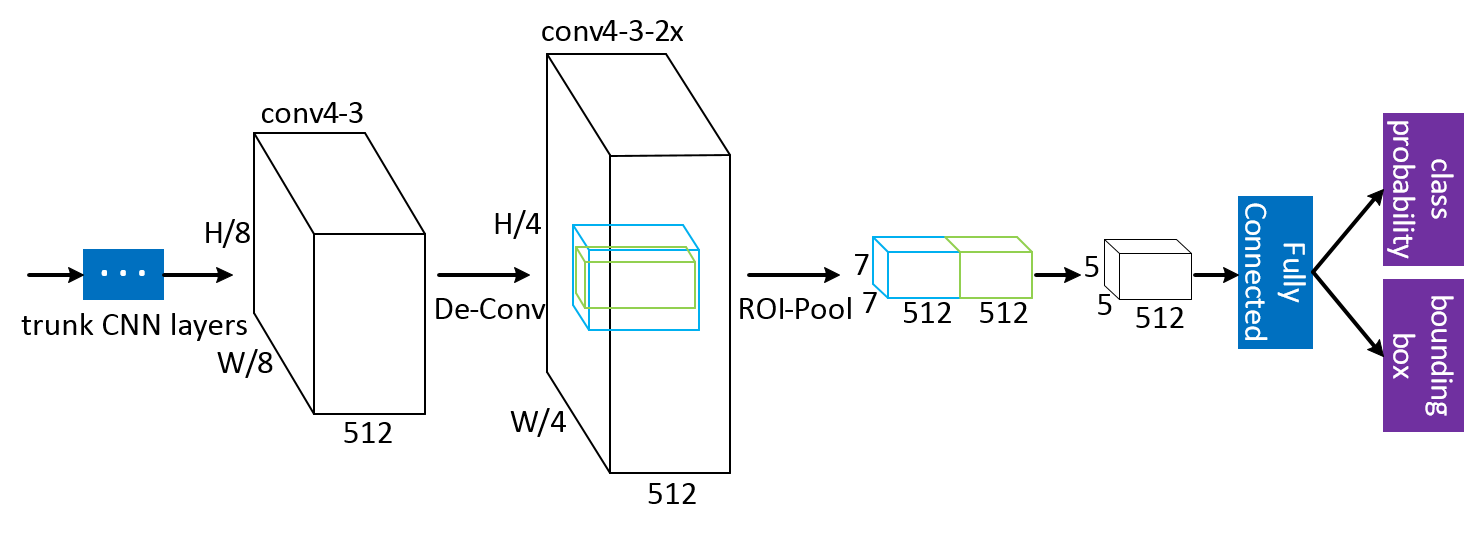
A detection network is added as the 2nd stage of the MS-CNN detecotr, with the detailed architecture shown above. The "trunk CNN layers" are shared with proposal sub-network, and then the feature maps are upsampled using a deconvolution layer to increase the resolution of feature maps. Features from an object (green cube) and a context (blue cube) region are stacked together immediately after ROI pooling, to be forwarded to the fully connected layer to make the final predicitons.