IMAGINE: Image Synthesis by Image-Guided Model Inversion
UC San Diego1, Adobe Research2
Published in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021

Overview
Synthesizing variations of a specific reference image with semantically valid content is an important task in terms of personalized generation as well as for data augmentation. In this work, we propose an inversion based method, denoted as IMAge-Guided model INvErsion (IMAGINE), to generate high-quality and diverse images only from one single training sample. We mainly leverage the knowledge of image semantics from a pre-trained classifier and achieve plausible generations via matching multi-level feature representations in the classifier, associated with adversarial training with an external discriminator. IMAGINE enables the synthesis procedure to be able to simultaneously 1) enforce semantic specificity constraints during the synthesis, 2) produce realistic images without the introduction of generator training, 3) allow fine controls over the synthesized image, and 4) be model-compact. With extensive experimental results, we demonstrate qualitatively and quantitatively that IMAGINE performs favorably against state-of-the-art GAN-based and inversion-based methods, across three different image domains, i.e., the object, scene and texture.
Image Generation

Position Control

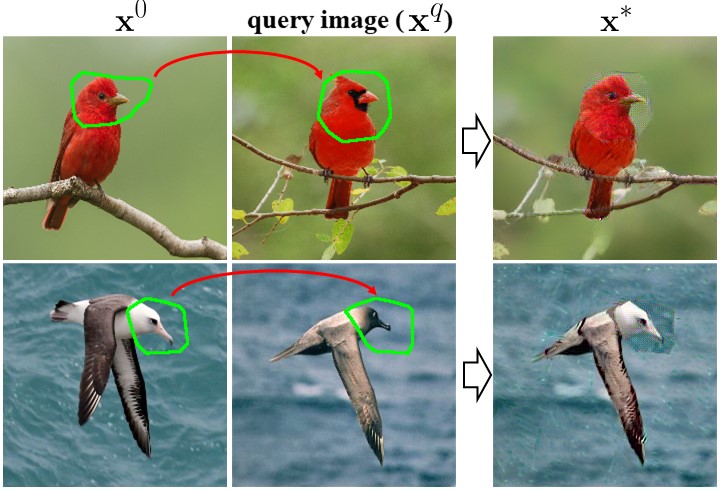
Shape Control

Style Control

Counterfactual Explanations