Overview
Current cutting-edge computer vision systems extensively rely on deep neural networks, which are heavy in terms of computation and memory, and require specialized expensive hardware, e.g. GPUs. Substantial speed-ups will be made possible if, both activations and weights of a network are binarized or quantized to low-bit, leveraging the property that the expensive float-point computation of dot-product can be replaced by efficient bit operations. However, this is challenging and suffers from substantial accuracy loss, especially when the activations are quantized. Thus, we investigated the problem of quantizing the activations for the speeds-up of neural networks. In previous binary quantization approaches, this problem consists of approximating a classical non-linearity, the hyperbolic tangent, by two functions: a piecewise constant sign function, which is used in feedforward network computations, and a piecewise linear tanh function, used in the backpropagation step during network learning.

Instead, we considered to approximate the widely used ReLU non-linearity. An half-wave Gaussian quantizer (HWGQ) is proposed for forward approximation and shown to have efficient implementation, by exploiting the statistics of network activations and batch normalization operations.
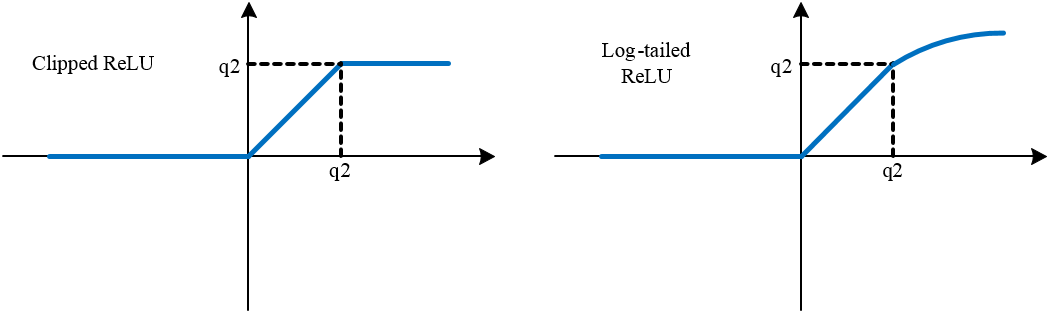
To overcome the problem of gradient mismatch, due to the use of different forward and backward approximations, several piece-wise backward approximators are then investigated, including a clipped ReLU and a log-tailed ReLU function. In the experiments, they have shown much better and more stable performance than the vanilla ReLU function. The implementation of the resulting quantized network, denoted as HWGQ-Net, achieves much closer performance to full precision networks, such as AlexNet, ResNet, GoogLeNet and VGG-Net, than previously available low-precision networks, with 1-bit binary weights and 2-bit quantized activations. This quantized networks can be used to significantly improve the running speeds and save power for deep neural networks, enabling them to run on non-GPU devices, e.g. CPU or FPGA.