Semi-supervised Long-tailed Recognition using Alternate Sampling
Haoxiang Li2
Hao Kang2
Gang Hua2
UC San Diego1, Wormpex AI Research2
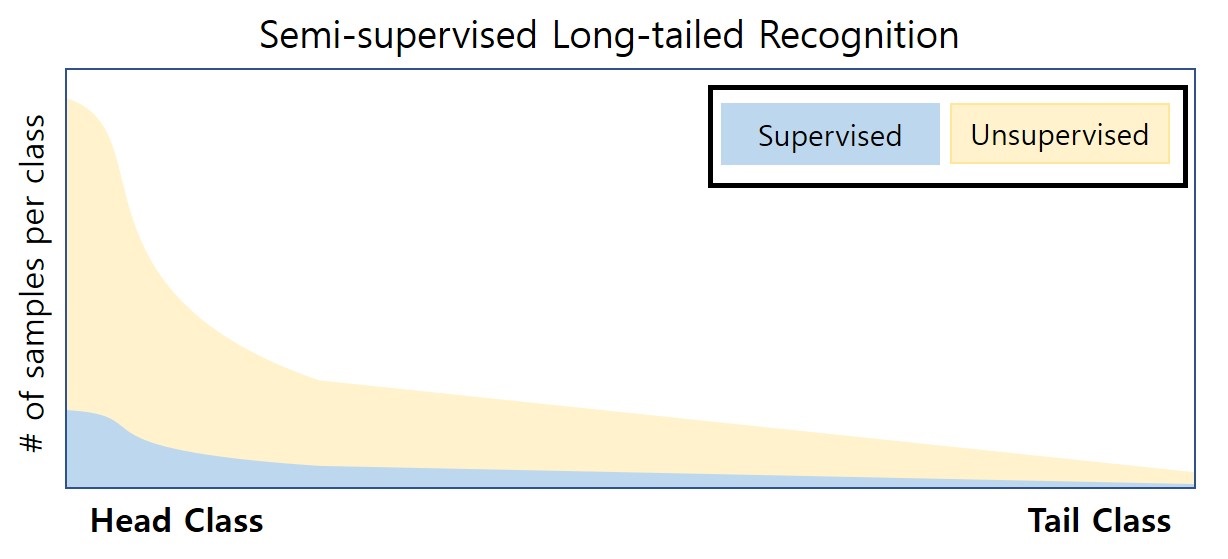
Overview
Main challenges in long-tailed recognition come from the imbalanced data distribution and sample scarcity in its tail classes. While techniques have been proposed to achieve a more balanced training loss and to improve tail classes data variations with synthesized samples, we resort to leverage readily available unlabeled data to boost recognition accuracy. The idea leads to a new recognition setting, namely semi-supervised long-tailed recognition. We argue this setting better resembles the real-world data collection and annotation process and hence can help close the gap to real-world scenarios. To address the semi-supervised long-tailed recognition problem, we present an alternate sampling framework combining the intuitions from successful methods in these two research areas. The classifier and feature embedding are learned separately and updated iteratively. The class-balanced sampling strategy has been implemented to train the classifier in a way not affected by the pseudo labels' quality on the unlabeled data. A consistency loss has been introduced to limit the impact from unlabeled data while leveraging them to update the feature embedding. We demonstrate significant accuracy improvements over other competitive methods on two datasets.

Models
Architecture: Training scheme of alternate sampling.
Algorithm
- Initialization: feature embedding, random classifier and class-balanced classifier are trained on the supervised subset.
- Alternate Learning
- Stage 1: Label assignement
- Stage 2: Semi-supervised learning with random sampling to fine-tune the feature embedding.
- Staeg 3: Supervised learning with class-balanced sampling to fine-tune the classifier.
Code
Training, evaluation and deployment code available on GitHub.
Datasets
All datasets are available on GitHub.
Authors


Haoxiang Li
Wormpex AI Research

Hao Kang
Wormpex AI Research


Gang Hua
Wormpex AI Research
Acknowledgements
Gang Hua was supported partly by National Key R&D Program of China Grant 2018AAA0101400 and NSFC Grant 61629301. Bo Liu and Nuno Vasconcelos were partially supported by NSF awards IIS-1637941, IIS-1924937, and NVIDIA GPU donations.