
Overview
While CNNs have enabled tremendous progress in computer vision for a variety of tasks, robust generalization across domain, viewpoint, and class remains a significant challenge. This project therefore centers around a new hierarchical multiview, multidomain image dataset with 3D meshes called 3D-ODDS. Data was collected in several ways, involving turntable setups, flying drones, and in-the-wild photos under diverse indoor/outdoor locations. Experiments were subsequently conducted on two important vision tasks: single view 3D reconstruction and image classification. For single view 3D reconstruction, a novel postprocessing step involving test-time self-supervised learning is proposed to help improve reconstructed shape robustness. For image classification, we consider an adversarial attack framework using perturbations which are semantically imperceptible based on human subject surveys. For both tasks, experiments show that 3D-ODDS is a challenging dataset for state of the art methods and is useful in measuring class, pose, and domain invariance. We believe that the dataset will remain relevant moving forward, inspiring future works towards robust and invariant methods in computer vision.
To read more, see the full M.S. thesis here.
Projects
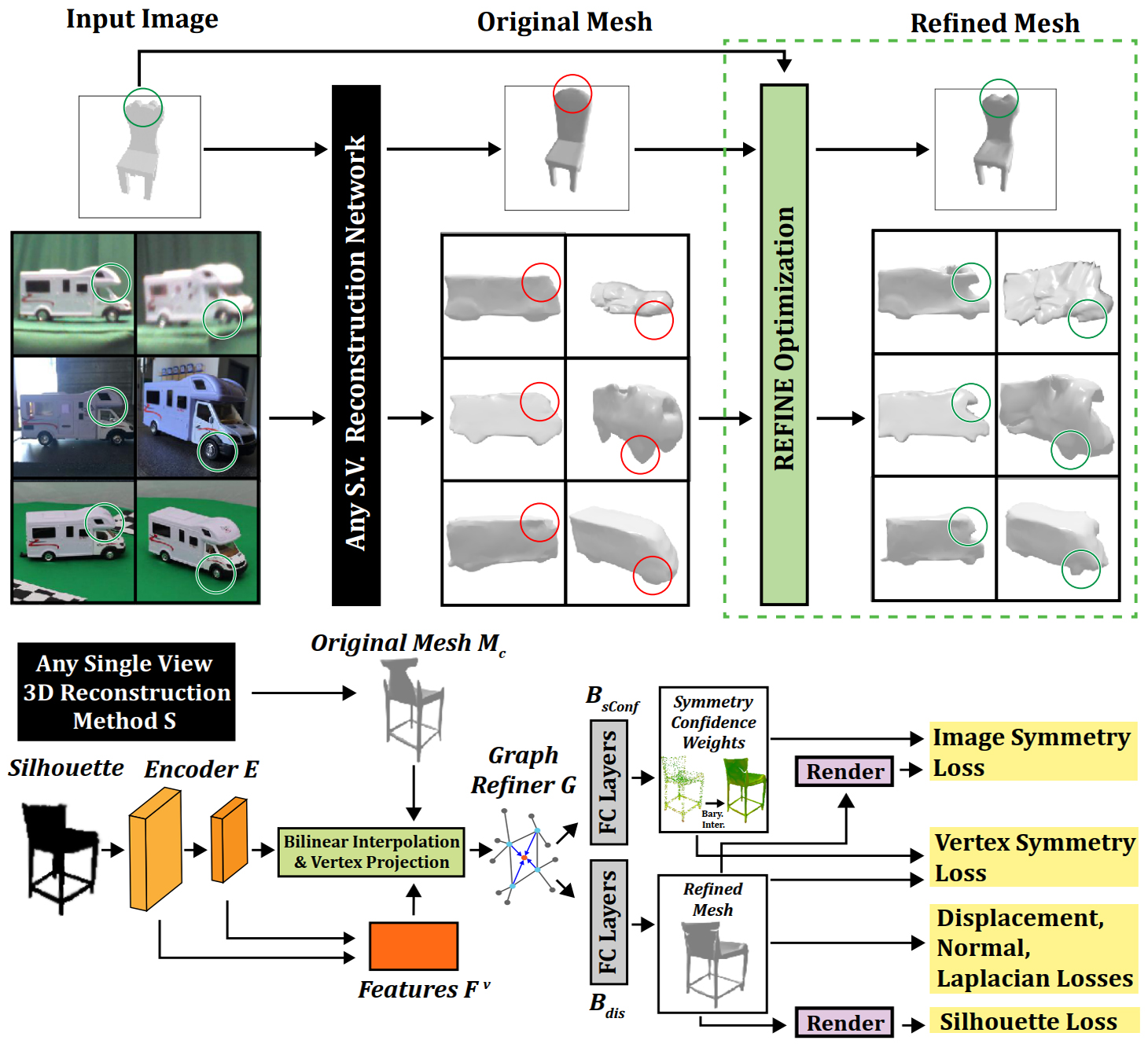
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Much recent progress has been made in reconstructing 3D object shape from an image, i.e. single view 3D reconstruction. However, due to the difficulty of collecting large datasets in the wild with 3D ground truth, it remains a significant challenge for methods to generalize across domain, viewpoint, and class. Current methods also tend to produce averaged “nearest-neighbor” memorized shapes instead of genuinely understanding the image, thus eliminating important details. To address this we propose REFINE, a postprocessing mesh refinement step easily integratable into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, with a novel combination of losses addressing degenerate solutions, reduces domain gap and restores details to achieve state of the art performance. A new hierarchical multiview, multidomain image dataset with 3D meshes called 3D-ODDS is also proposed as a uniquely challenging benchmark. We believe that the novel REFINE paradigm and 3D-ODDS are important steps towards truly robust, accurate 3D reconstructions.
Catastrophic Child’s Play: Easy to Perform, Hard to Defend Adversarial Attacks
The problem of adversarial CNN attacks is considered, with an emphasis on attacks that are trivial to perform but difficult to defend. A framework for the study of such attacks is proposed, using real world object manipulations. Unlike most works in the past, this framework supports the design of attacks based on both small and large image perturbations, implemented by camera shake and pose variation. A setup is proposed for the collection of such perturbations and determination of their perceptibility. It is argued that perceptibility depends on context, and a distinction is made between imperceptible and semantically imperceptible perturbations. While the former survives image comparisons, the latter are perceptible but have no impact on human object recognition. A procedure is proposed to determine the perceptibility of perturbations using Turk experiments, and a dataset of both perturbation classes which enables replicable studies of object manipulation attacks, is assembled. Experiments using defenses based on many datasets, CNN models, and algorithms from the literature elucidate the difficulty of defending these attacks -- in fact, none of the existing defenses is found effective against them. Better results are achieved with real world data augmentation, but even this is not foolproof. These results confirm the hypothesis that current CNNs are vulnerable to attacks implementable even by a child, and that such attacks may prove difficult to defend.

Publications
Understanding Learned Visual Invariances Through Hierarchical Dataset Design and Collection
Brandon Leung
M.S. Thesis, University of California San Diego,
2022.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Brandon Leung, Chih-Hui Ho, Nuno Vasconcelos
IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR)
Workshop on Learning with Limited Labelled Data for Image and Video Understanding, 2022.
Catastrophic Child’s Play: Easy to Perform, Hard to Defend Adversarial Attacks
Chih-Hui Ho*, Brandon Leung*, Erik Sandström, Yen Chang, Nuno Vasconcelos
IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR),
2019.
Acknowledgements
This work was partially funded by NSF awards IIS-1546305 and IIS-1637941, a gift from Northrop Grumman, and NVIDIA GPU donations. It was also partially funded by support given to me from the National Science Foundation (NSF) in the form of a GRFP fellowship given to me. I am also grateful for support from a Alfred P. Sloan Foundation fellowship, a UCSD STARS fellowship, and UC LEADS. We also acknowledge and thank the use of the Nautilus platform for some of the experiments in the papers above.